
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 데이터 구축
- KLUE
- Data Viz
- Transformer
- matplotlib
- pyTorch
- 기아
- dataset
- Optimization
- Ai
- AI 경진대회
- N21
- 현대자동차
- seaborn
- Bert
- RNN
- Attention
- passage retrieval
- N2N
- 데이터 시각화
- word2vec
- 2023 현대차·기아 CTO AI 경진대회
- GPT
- AI Math
- ODQA
- 딥러닝
- Bart
- nlp
- mrc
- Self-attention
Archives
- Today
- Total
쉬엄쉬엄블로그
(딥러닝) Transformer 본문
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
Sequential Model
What makes sequential modeling a hard problem to handle?

- 중간에 어떤 단어가 빠지거나 순서가 뒤바뀌는 단어가 있으면 모델링하기 어렵게 됨
Transformer
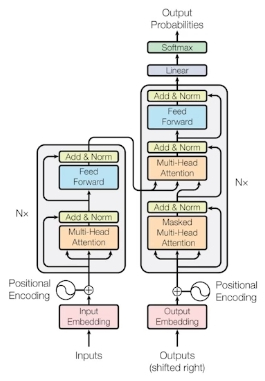
- Transformer is the first sequence transduction model based entirely on attention.
- Transformer는 전적으로 attention에 기초한 최초의 시퀀스 변환 모델이다.
- From a bird’s-eye view, this is what the Transformer does for machine translation tasks.
- 대략적인 관점에서, 아래 그림은 Transformer가 기계 번역 작업에 수행하는 작업이다.

- NLP뿐만 아니라 이미지 분류, 이미지 검출 등에도 다양하게 활용됨
- 대략적인 관점에서, 아래 그림은 Transformer가 기계 번역 작업에 수행하는 작업이다.
- If we glide down a little bit, this is what the Transformer does.
- 다음 그림들은 Transformer가 수행하는 작업이다.


- 입력 sequence와 출력 sequence의 길이, 도메인이 다를 수 있음


- 다음 그림들은 Transformer가 수행하는 작업이다.
- The Self-Attention in both encoder and decoder is the cornerstone of Transformer.
- encoder와 decoder의 Self-Attention은 Transformer의 초석이다.

- First, we represent each word with some embedding vectors.
- 먼저, 각 단어를 embedding vectors로 나타낸다.

- Then, Transformer encodes each word to feature vectors with Self-Attention.
- 그 후, Transformer가 각 단어를 Self-Attention읉 통해 feature vectors로 인코딩한다.

"The animal didn't cross the street because it was too tired" 라는 문장에서 "it"은 무엇을 의미하는지 Transformer가 학습하는 방법?

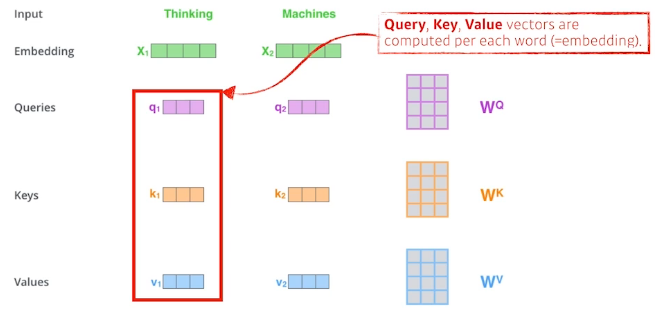
- Suppose we are encoding two words
- Thinking and Machines.
- Thinking과 Machines라는 두 단어를 인코딩한다고 가정해보자
- Self-Attention at a high level
- Query, Key, Value 벡터들이 각각의 단어(임베딩된 단어)들과 계산된다.
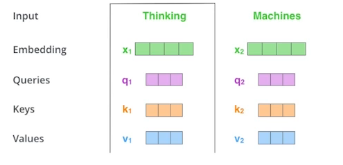
- 두 단어 중 첫 번째 단어인 "Thinking"을 인코딩한다고 가정해보자
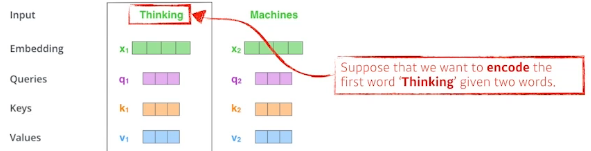
- 그럼 각 단어들에 대해서 score를 계산할 필요가 있다.

- 첫 번째 단어(Thinking)를 인코딩할 때(score를 계산할 때), corresponding query vector가 사용된다.
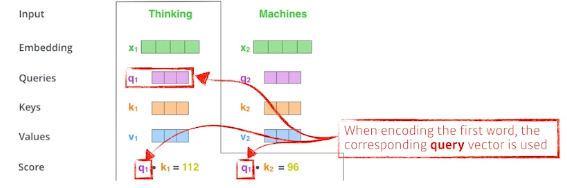
- corresponding key vectors를 사용하여 주어진 모든 단어들의 점수를 계산한다.


- Query, Key, Value 벡터들이 각각의 단어(임베딩된 단어)들과 계산된다.
- Suppose we are encoding the first word : ‘Thinking’ given ‘Thinking’ and ‘Machines’.
- 'Thinking'과 'Machines' 두 단어가 주어졌을 때 첫 번째 단어인 Thinking을 인코딩한다고 가정하자

- We compute the scores of each word with respect to ‘Thinking’.
- Thinking과 관련된 각 단어들에 대해 score를 계산한다.
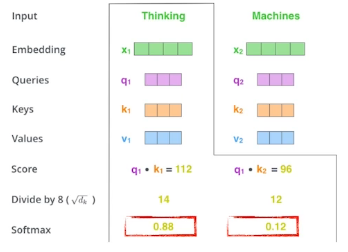
- Then, we compute the attention weights by scaling followed by softmax.
- 그 후, softmax를 통해 scaling함으로써 attention weights를 계산한다.
- 8로 나눠서 정규화 해줌
- 8은 key vector dimension에 의해서 나온 값
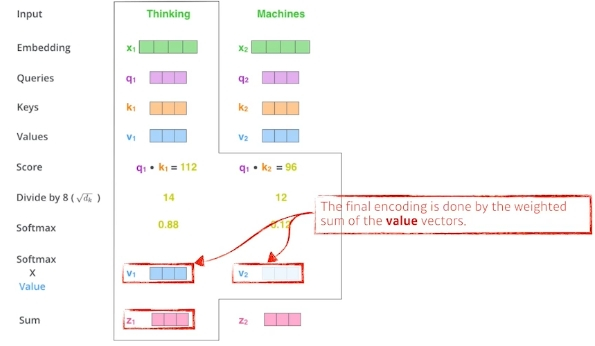
- value vectors들의 가중합에 의해 마지막 인코딩이 수행된다.
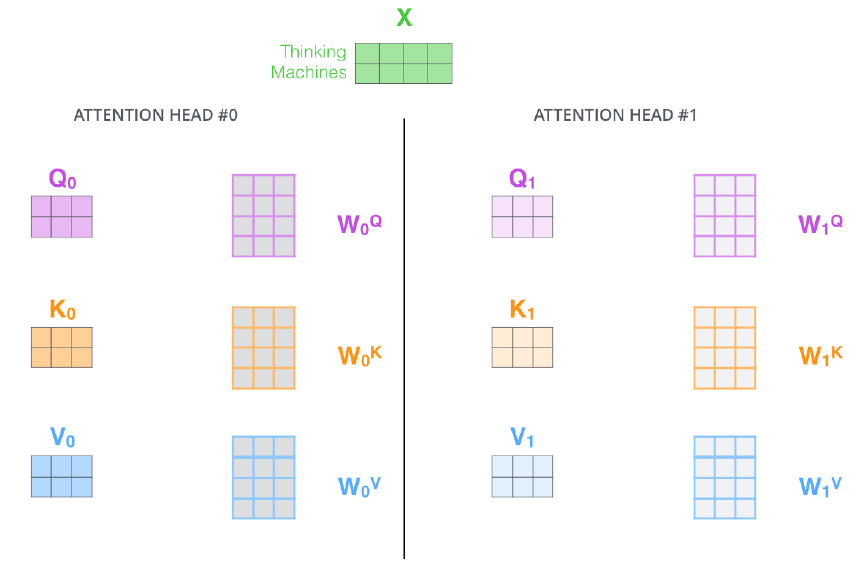
- Calculating Q, K, and V from X in a matrix form.
- X 행렬에서 Query, Key, Value 계산하는 방법을 나타낸 그림

- X 행렬에서 Query, Key, Value 계산하는 방법을 나타낸 그림

- 입력이 고정되더라도 옆에 주어진 입력들이 달라짐에 따라서 출력이 달라질 수 있는 여지가 있는 구조가 transformer
- 그래서 훨씬 더 많은 것을 표현할 수 있음
- 바꿔말하면 더 많은 것을 표현하기 때문에 더 많은 연산이 필요함
- n개의 단어가 주어지면 기본적으로 n x n attention map을 만들어야 함
- 한 번에 처리하고자 하는 단어가 1000개면 1000 x 1000 입력을 처리해야 함
- 길이가 길어짐에 따라서 처리할 수 있는 한계 발생
- n개의 단어가 주어지면 기본적으로 n x n attention map을 만들어야 함
- Multi-headed attention (MHA) allows Transformer to focus on different positions.
- MHA를 통해 Transformer는 다양한 위치에 집중할 수 있음
- MHA를 통해 Transformer는 다양한 위치에 집중할 수 있음
- If eight heads are used, we end up getting eight different sets of
encoded vectors (attention heads).- 만약 8개의 head를 사용한다면, 8개의 서로 다른 인코딩된 벡터셋들(attention heads)을 얻을 수 있음
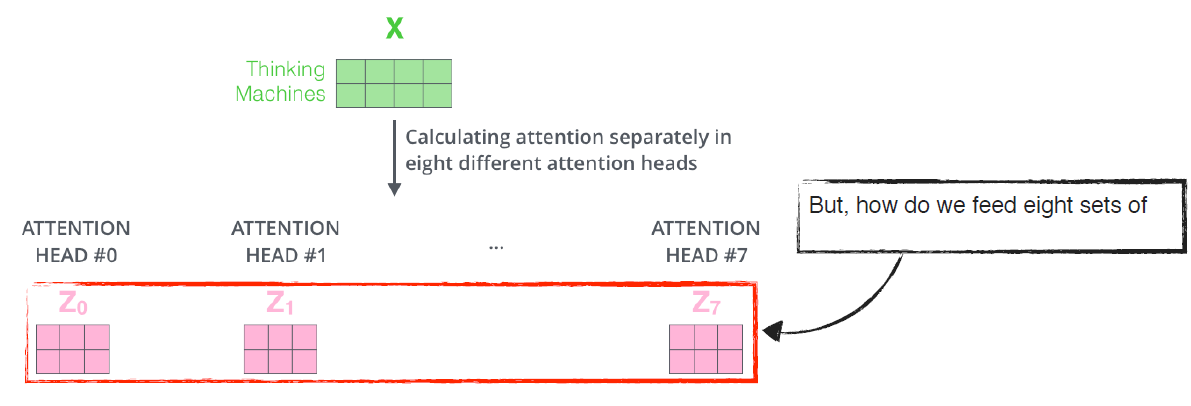
- 만약 8개의 head를 사용한다면, 8개의 서로 다른 인코딩된 벡터셋들(attention heads)을 얻을 수 있음
- We simply pass them through additional (learnable) linear map.
- 인코딩된 벡터셋들을 추가적인 (학습가능한) 선형 맵을 통해 간단히 전달함


- 인코딩된 벡터셋들을 추가적인 (학습가능한) 선형 맵을 통해 간단히 전달함
- Why do we need positional encoding?
- positional encoding이 필요한 이유?
- sequential 정보를 넣어주기 위해 사용
- 주어진 입력에 어떤 값을 더해줌

- This is the case for 4-dimensional encoding.
- 4차원 positional encoding 예시

- 4차원 positional encoding 예시
- This is the case for 512-dimensional encoding.
- 512차원 positional encoding 예시

- 512차원 positional encoding 예시
- Recent (July, 2020) update on positional encoding.
- 최근 positional encoding 예시
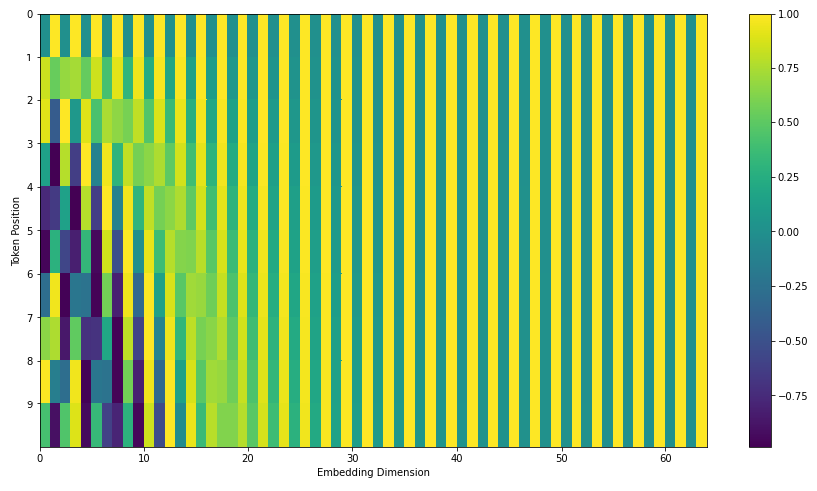
- 최근 positional encoding 예시
- Now, let’s take a look at the decoder side.
- decoder 부분을 살펴보자
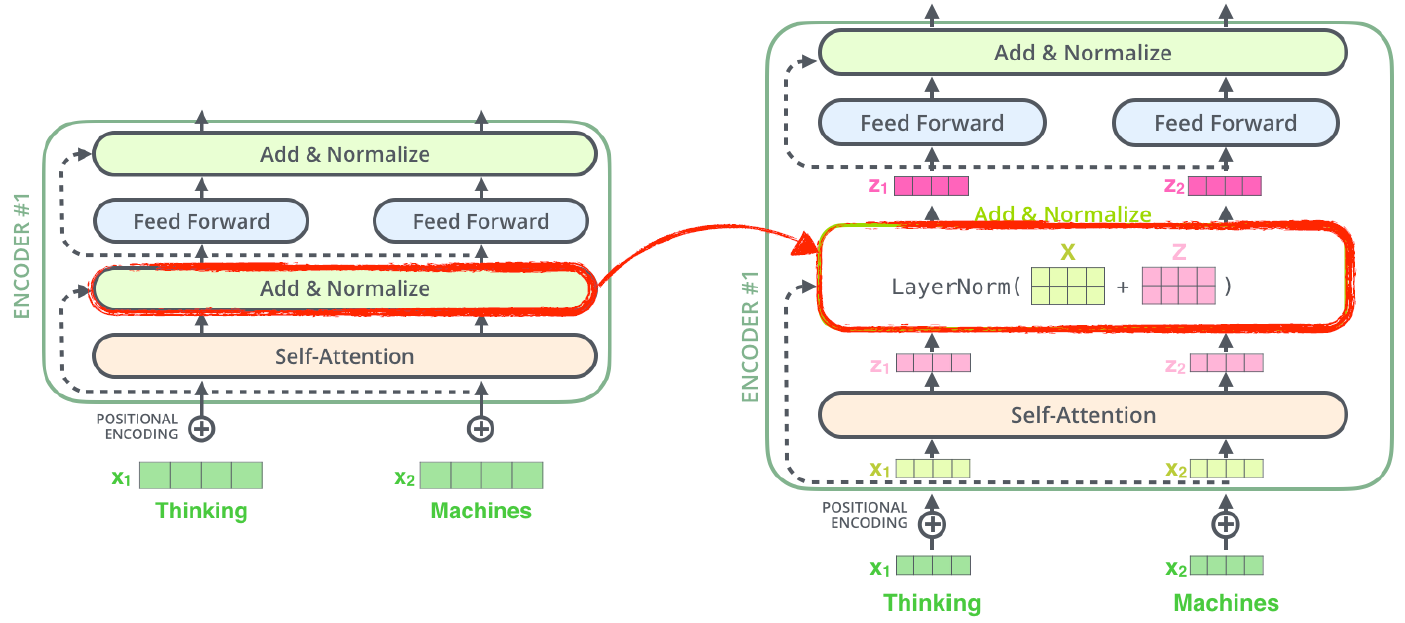
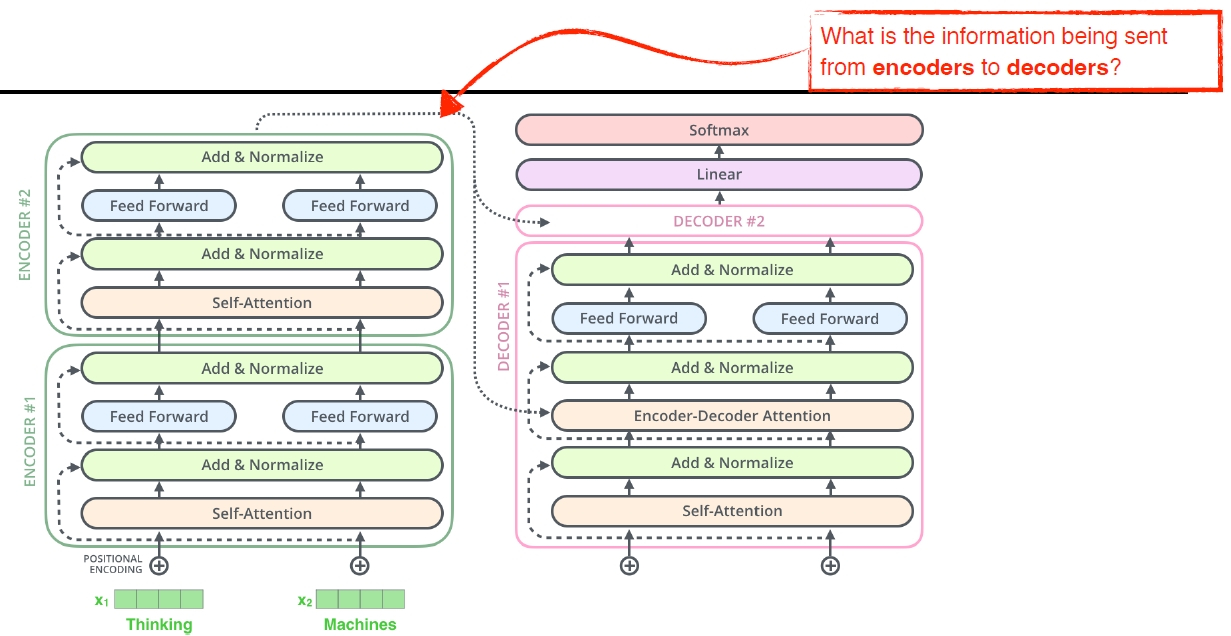
- decoder 부분을 살펴보자
- Transformer transfers key (K) and value (V) of the topmost encoder to the decoder.
- Transformer는 최상위 인코더의 키(K)와 값(V)을 디코더로 보냄
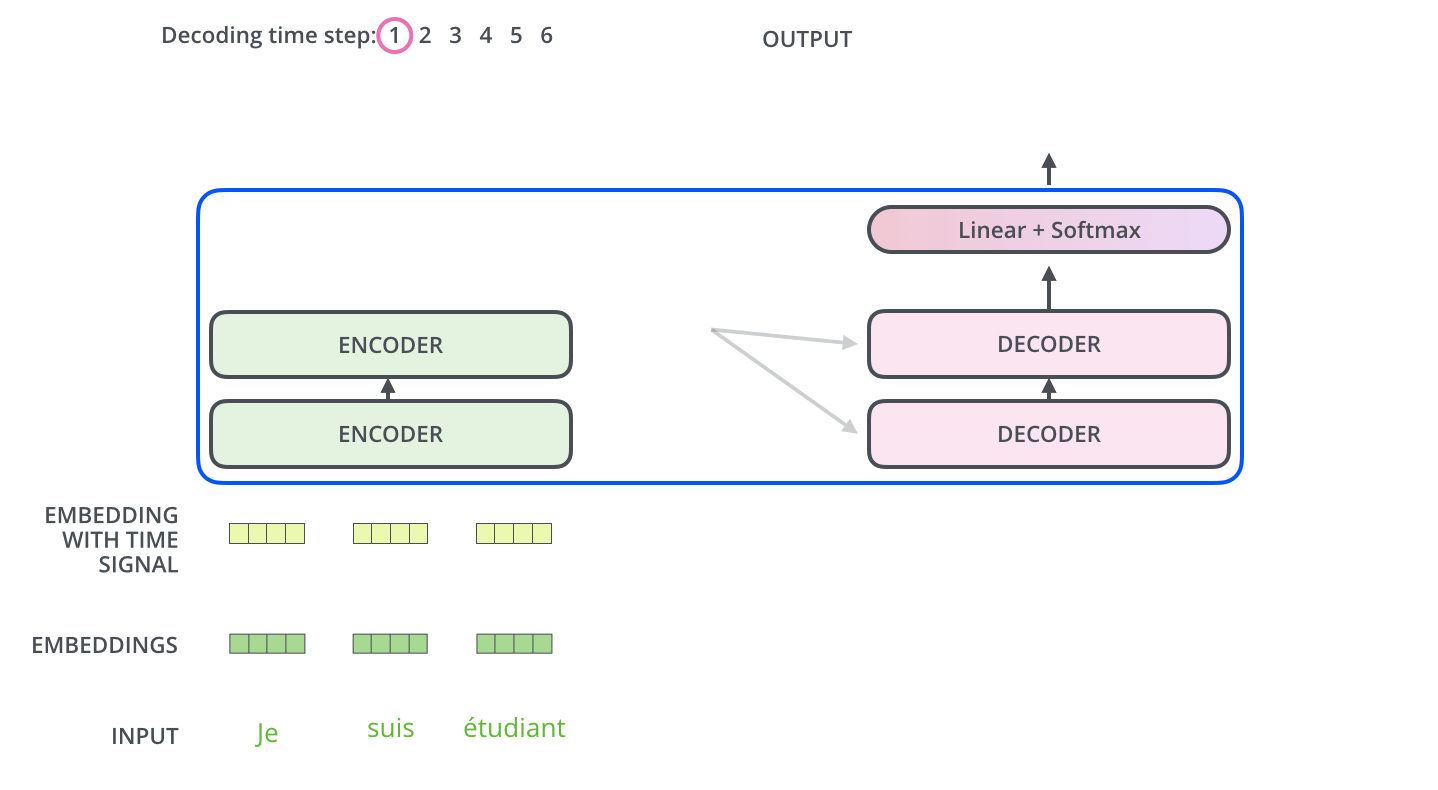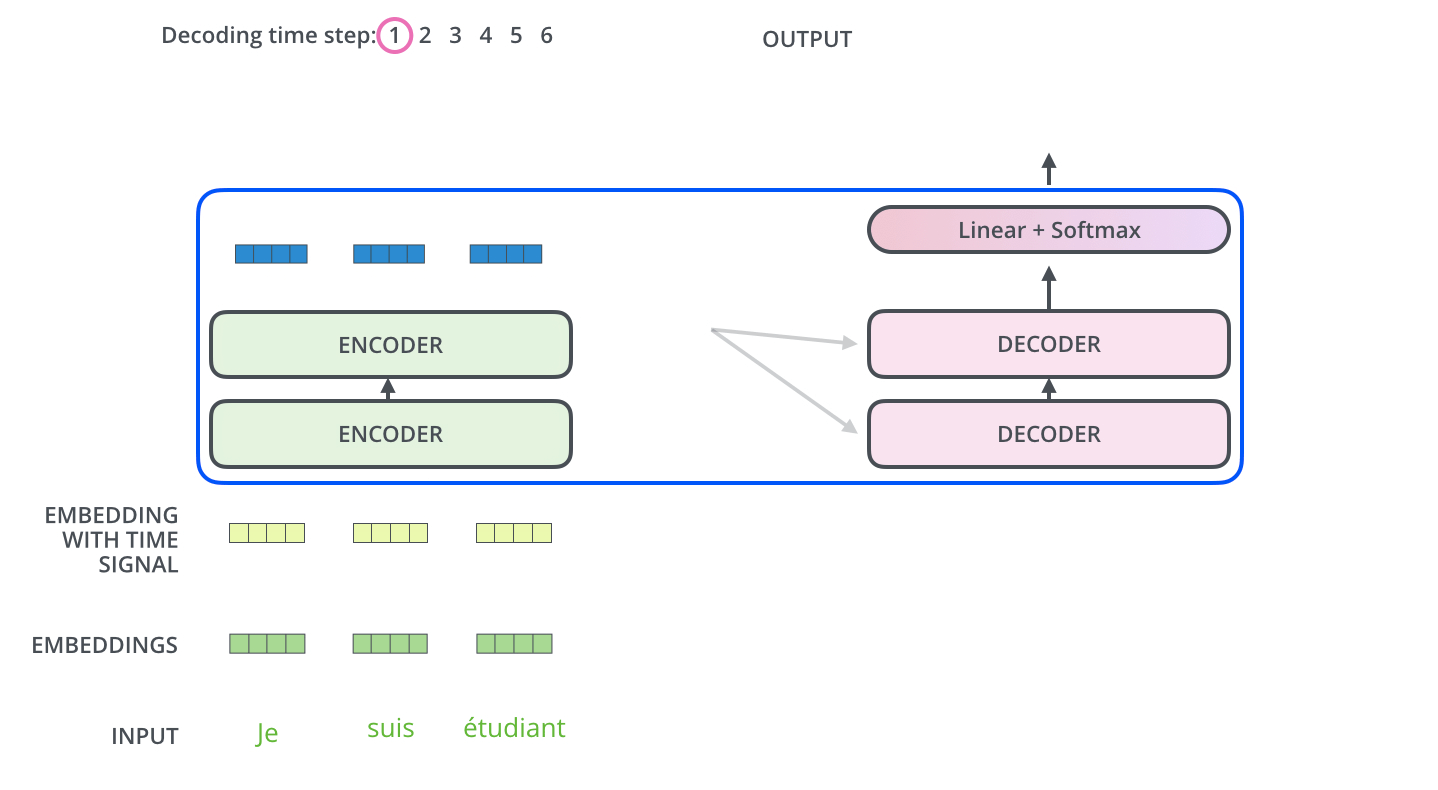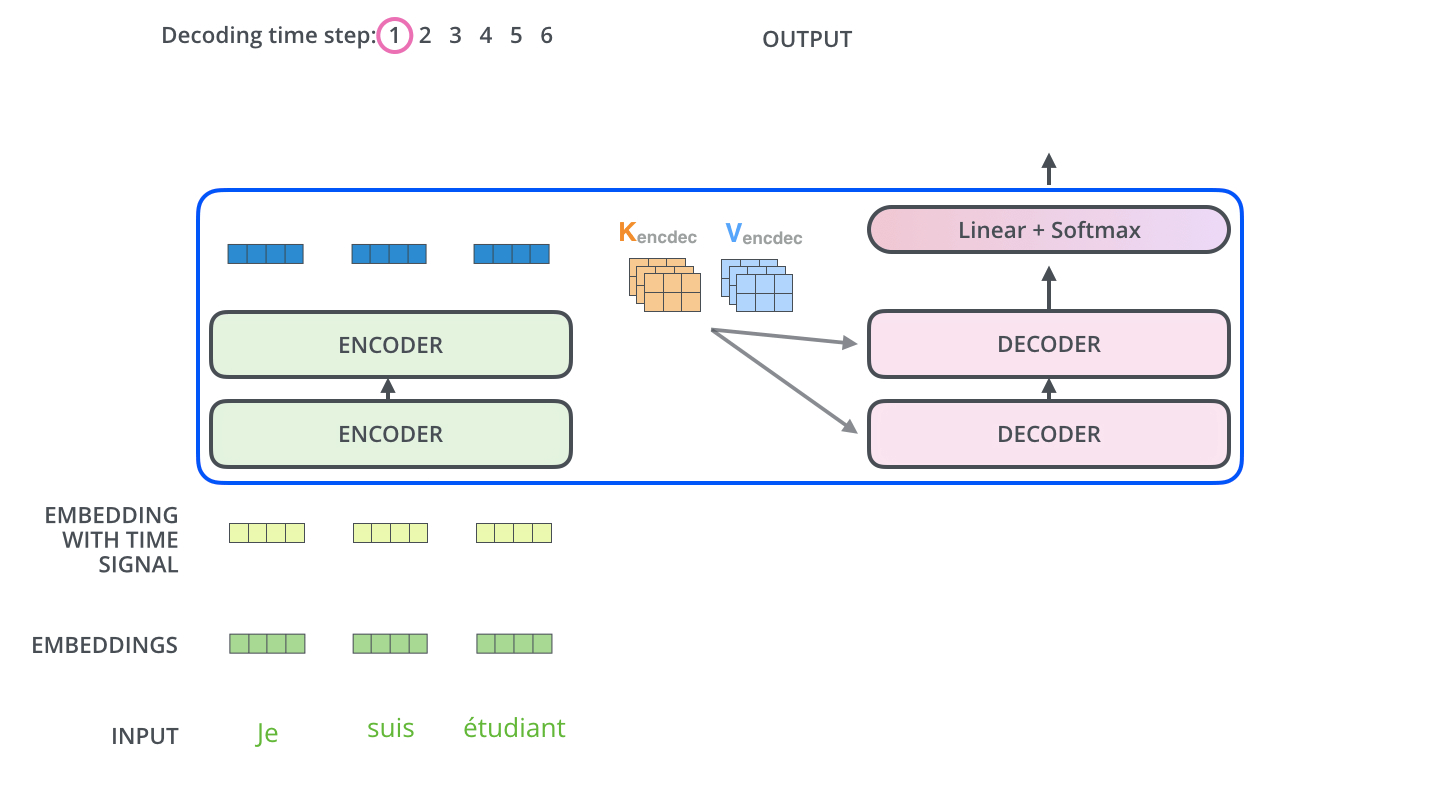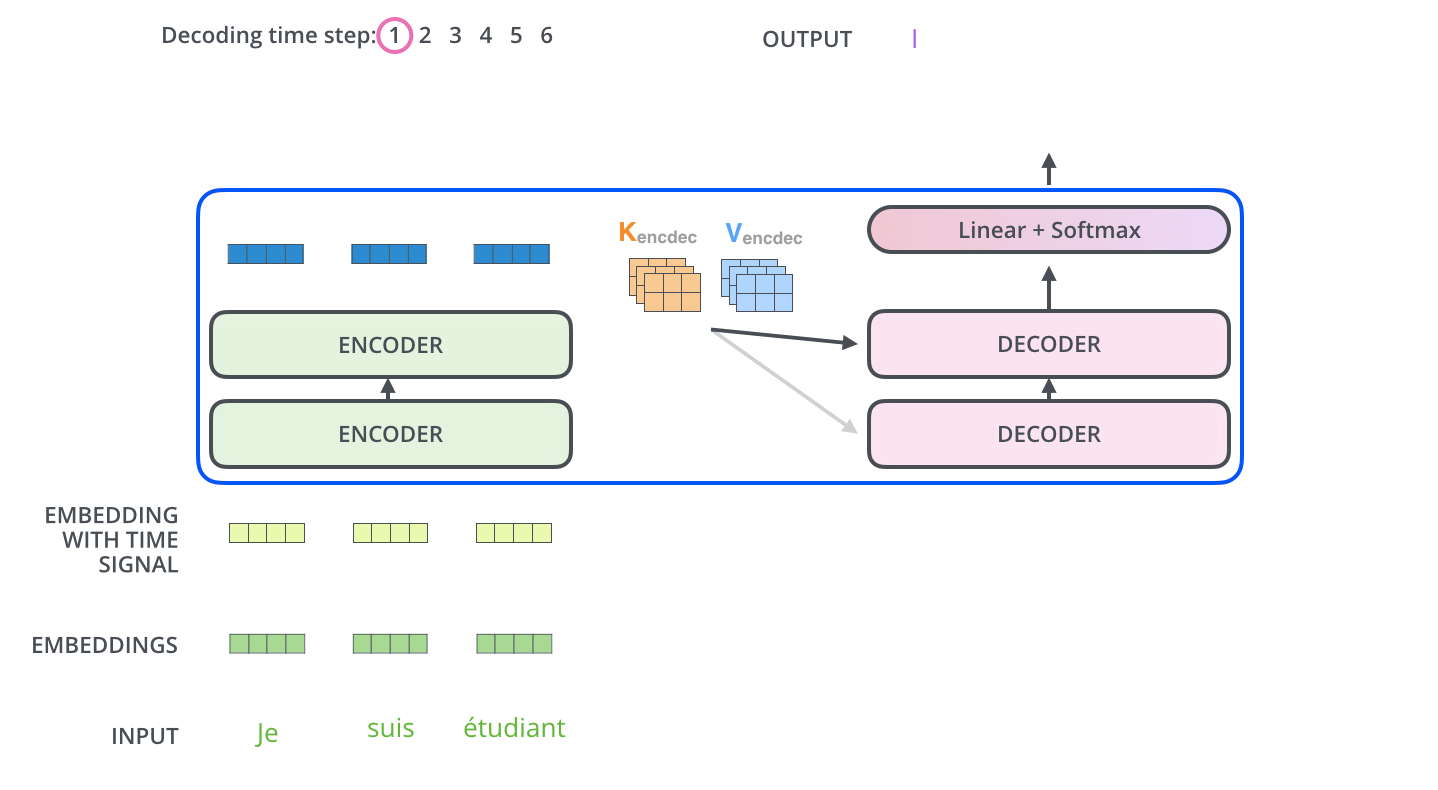
- Transformer는 최상위 인코더의 키(K)와 값(V)을 디코더로 보냄
- The output sequence is generated in an autoregressive manner.
- 출력 시퀀스는 autoregressive 방식으로 만들어짐
- autoregressive : 이전 입력을 통해 다음 출력을 만듬

- autoregressive : 이전 입력을 통해 다음 출력을 만듬
- 출력 시퀀스는 autoregressive 방식으로 만들어짐
- In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence which is done by masking future positions before the softmax step.
- 디코더에서 self-attention 레이어는 softmax 단계 이전의 미래 위치를 masking함으로써 이전 위치의 출력 시퀀스에 집중할 수 있음

- 디코더에서 self-attention 레이어는 softmax 단계 이전의 미래 위치를 masking함으로써 이전 위치의 출력 시퀀스에 집중할 수 있음
- The “Encoder-Decoder Attention” layer works just like multi-headed self attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values from the encoder stack.
- Encoder-Decoder Attention 레이어는 아래 레이어에서 쿼리 행렬을 만들고 인코더 스택에서 key와 value를 가져온다는 점을 제외하면 multi-headed self-attention과 똑같이 동작함
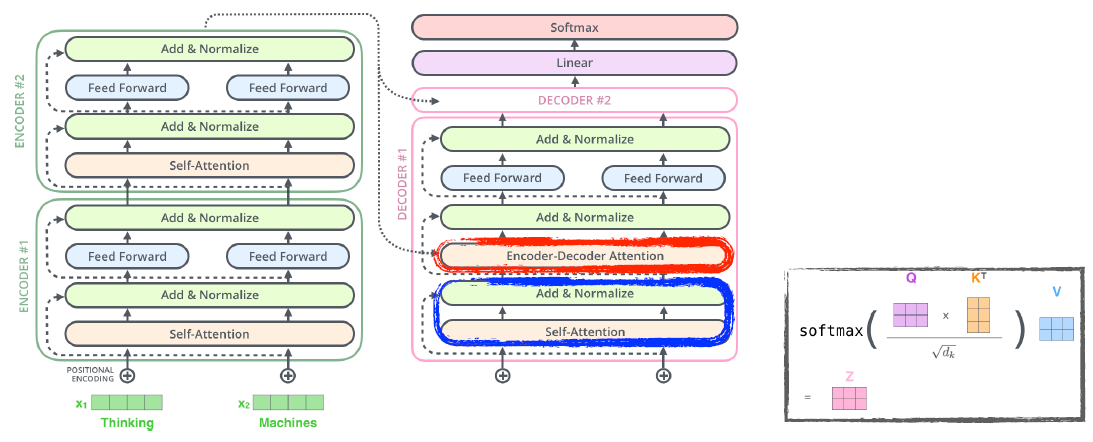
- Encoder-Decoder Attention 레이어는 아래 레이어에서 쿼리 행렬을 만들고 인코더 스택에서 key와 value를 가져온다는 점을 제외하면 multi-headed self-attention과 똑같이 동작함
- The final layer converts the stack of decoder outputs to the distribution over words.
- 최종 레이어는 디코더 출력의 stack을 단어들에 대한 분포로 변환시킴

- 최종 레이어는 디코더 출력의 stack을 단어들에 대한 분포로 변환시킴
Vision Transformer

DALL-E
- An armchair in the shape of an avocado.

https://openai.com/blog/dall-e/
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (딥러닝) Generative Models - 2 (0) | 2023.06.05 |
|---|---|
| (딥러닝) Generative Models - 1 (0) | 2023.06.03 |
| (딥러닝) Recurrent Neural Networks (0) | 2023.06.01 |
| (딥러닝) Computer Vision Applications (0) | 2023.05.31 |
| (딥러닝) Modern Convolutional Neural Networks (0) | 2023.05.30 |
'부스트캠프 AI Tech 4기' Related Articles
more




Comments