
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- pyTorch
- Transformer
- 현대자동차
- Ai
- Bert
- nlp
- 기아
- KLUE
- AI 경진대회
- 2023 현대차·기아 CTO AI 경진대회
- Optimization
- Bart
- matplotlib
- ODQA
- passage retrieval
- 데이터 구축
- Data Viz
- 딥러닝
- RNN
- N21
- AI Math
- Attention
- dataset
- seaborn
- mrc
- N2N
- Self-attention
- GPT
- 데이터 시각화
- word2vec
Archives
- Today
- Total
쉬엄쉬엄블로그
(딥러닝) Recurrent Neural Networks 본문
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
Sequential Model
Naive sequence model
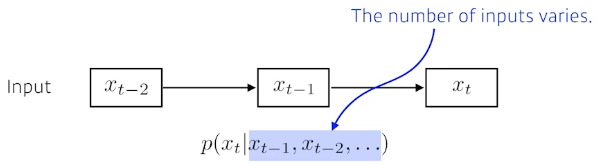
Sequential Model(Data)을 다루는데 어려운 점
- Sequential Data는 길이가 언제 끝날지 모름
- 입력으로 받아들여야 하는 차원을 알 수 없음
- 그래서 Convolution Neural Network를 사용할 수가 없음
- 과거에 내가 고려해야하는 정보량이 점점 늘어남
Autoregressive model

- 과거 timestep t개의 결과를 현재 예측에 활용
- 과거의 결과를 현재 예측에 활용하는 것을 autoregressive하다고 표현
Markov model (first-order autoregressive model)

Latent autoregressive model

- 중간에 hidden state가 들어가있고 hidden state가 과거의 정보를 요약해서 가지고 있음
- 그래서 다음 cell state는 이전 hidden state만 참고해도 과거의 정보를 어느정도 전달받게 됨
Recurrent Neural Network


Short-term dependencies

Long-term dependencies

RNN의 문제

- $h_0$ 값이 $h_4$로 갈 때 Vanishing gradient가 발생하여 학습이 되지 않는 현상이 발생
Long Short Term Memory
- RNN의 문제점을 보완하기 위해 LSTM 제안
Vanilla RNN

LSTM


Previous cell state : timestep t까지의 정보를 요약해줌
입력이 3개
- Previous cell state
- Previous hidden state
- Input
출력도 3개
- Next cell state
- Next hidden state
- Output
Core idea


sigmoid를 통과하기 때문에 0~1 사이의 값을 갖게 됨
이전 hidden state에서 나온 정보 중에 현재 입력을 바탕으로 어떤 것을 버리고 살릴지 정하게 됨

입력으로 들어온 정보 중에 어떤 정보를 올릴지 말지 정하게 됨
$i_t$ : 이전 hidden state와 현재 입력을 가지고 sigmoid를 적용하여 만드는 값
$\tilde C_t$ : 이전 hidden state와 현재 입력을 가지고 tanh를 적용하여 나오는 모든 값이 -1 ~ 1로 정규화된 값
- 현재 정보와 이전 출력 값을 가지고 만드는 cell state의 예비군

버릴 값은 버리고 쓸 값은 쓰도록 만들게 됨
Input Gate에서 나왔던 $\tilde C_t$를 가지고 $i_t$ 값만큼 곱한 값과
Forget Gate에서 나왔던 $f_t$를 이전 cell state 값만큼 곱한 값,
두 값을 더한 것을 새로운 cell state로 update함
어떤 값을 밖으로 내보낼지 정하게 됨
$o_t$ : 이전 cell state와 현재 입력을 가지고 sigmoid를 적용하여 만드는 값
$o_t$와 $C_t$(update cell에서 나온 값)에 tanh를 적용한 값을 곱하여 출력 값을 만듬
To summarize

- Input, Previous cell state, Previous hidden state 가 뉴럴 네트워크 안으로 들어오게 되면 먼저 이전 cell state를 얼마만큼 지울지 정함
- Previous hidden state와 input을 가지고 어떤 값을 올릴지 $\tilde C_t$를 정함
- update된 cell state와 현재 내가 올릴 candidate cell state를 조합하여 새로운 cell state를 만들고 그 정보를 얼마만큼 밖으로 빼낼지 정해서 최종적인 출력값을 정함
Gated Recurrent Unit

- Simpler architecture with two gates (reset gate and update gate).
- reset gate, update gate를 가진 LSTM보다 더 간단한 구조
- No cell state, just hidden state.
- LSTM과 다르게 cell state와 hidden state가 없음
- LSTM보다 GRU를 활용할 때 성능이 더 좋은 경우가 많음
- GRU가 LSTM보다 파라미터가 적고 동일한 출력이 나올 때 파라미터가 적은 쪽이 generalize performance가 상승하기 때문
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (딥러닝) Generative Models - 1 (0) | 2023.06.03 |
|---|---|
| (딥러닝) Transformer (0) | 2023.06.02 |
| (딥러닝) Computer Vision Applications (0) | 2023.05.31 |
| (딥러닝) Modern Convolutional Neural Networks (0) | 2023.05.30 |
| (딥러닝) Convolutional Neural Networks (1) | 2023.05.30 |
'부스트캠프 AI Tech 4기' Related Articles
more




Comments