
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- matplotlib
- 기아
- seaborn
- Ai
- 2023 현대차·기아 CTO AI 경진대회
- word2vec
- N2N
- ODQA
- RNN
- 딥러닝
- Bert
- Attention
- AI Math
- 현대자동차
- KLUE
- 데이터 시각화
- Optimization
- mrc
- dataset
- 데이터 구축
- passage retrieval
- Bart
- GPT
- N21
- Data Viz
- nlp
- Self-attention
- Transformer
- AI 경진대회
- pyTorch
- Today
- Total
쉬엄쉬엄블로그
(MRC) QA with Phrase Retrieval 본문
이 색깔은 주석이라 무시하셔도 됩니다.
QA with Phrase Retrieval
Phrase Retrieval in Open-Domain Question Answering
Current limitation of Retriever-Reader approach
Error Propagation : 5~10개의 문서만 reader에게 전달됨
Query-dependent encoding : query에 따라 정답이 되는 answer span에 대한 encoding이 달라짐
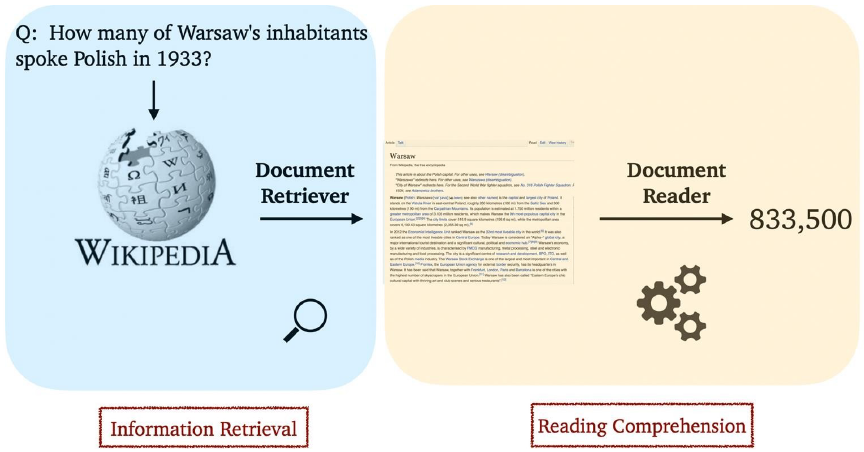
How does Document Search work?
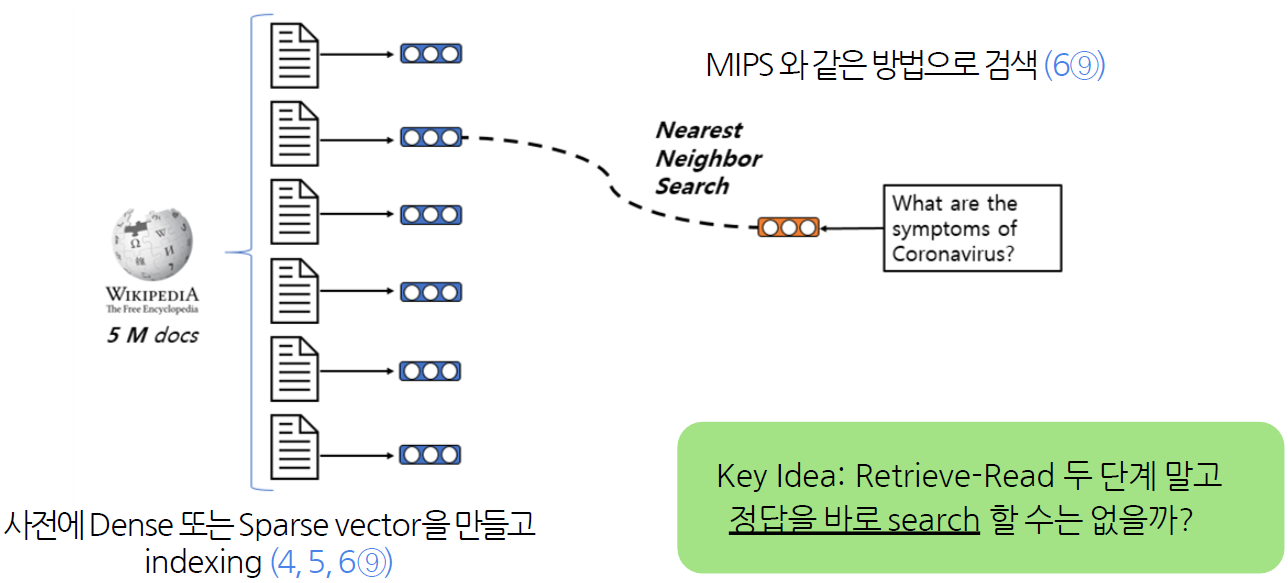
One solution : Phrase Indexing
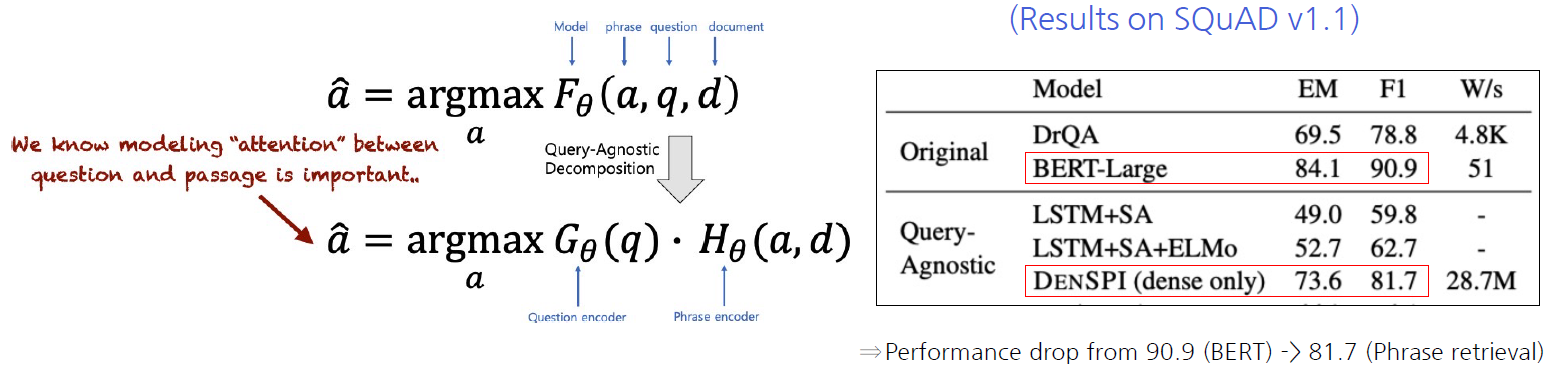
Query-Agnostic Decomposition
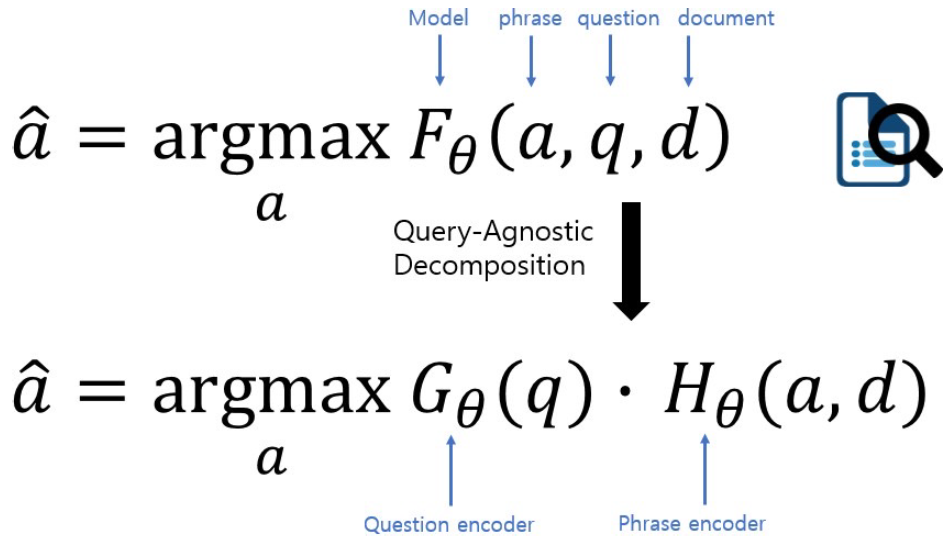
F가 G와 H로 나뉠 수 있다는 가정이 필요함
- 따라서 실질적으로 정확히 decompose하기보다는 G와 H를 학습하되 최대한 F를 흉내내도록 근사하는 방법으로 갈 수 밖에 없음

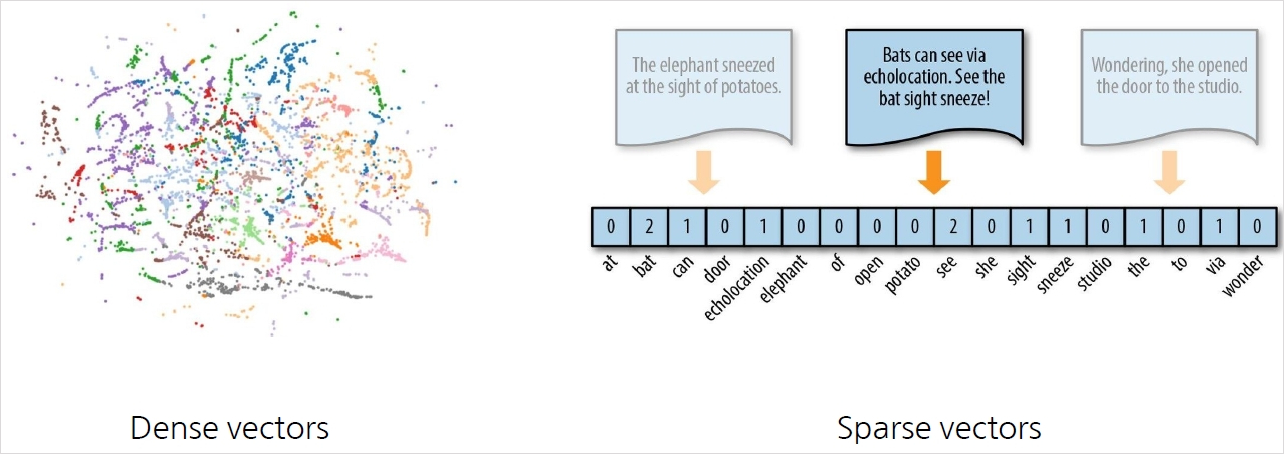
Dense-sparse Representation for Phrases
Dense vectors vs Sparse vectors
Dense vectors : 통사적, 의미적 정보를 담는 데 효과적
Sparse vectors : 어휘적 정보를 담는 데 효과적
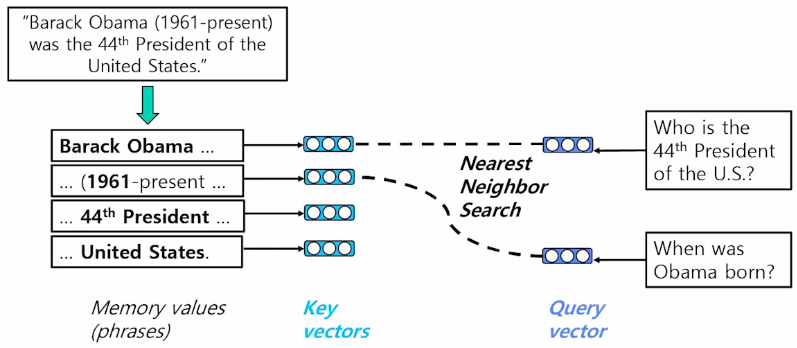
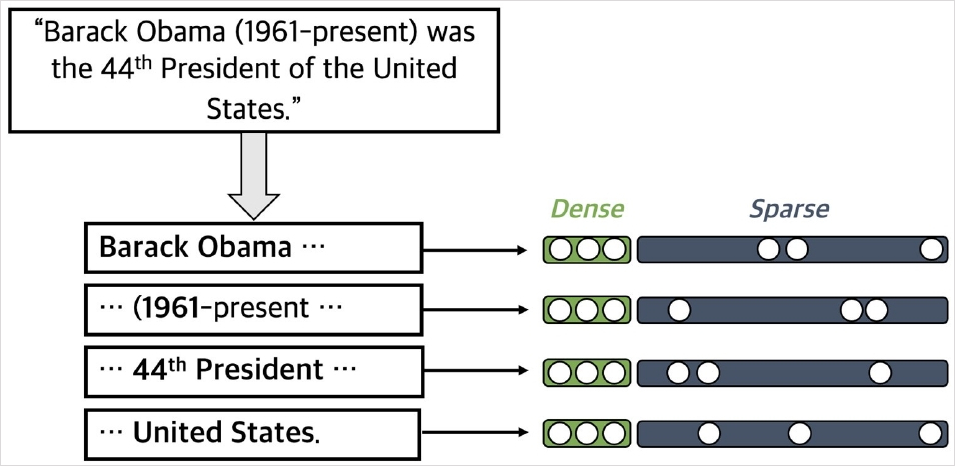
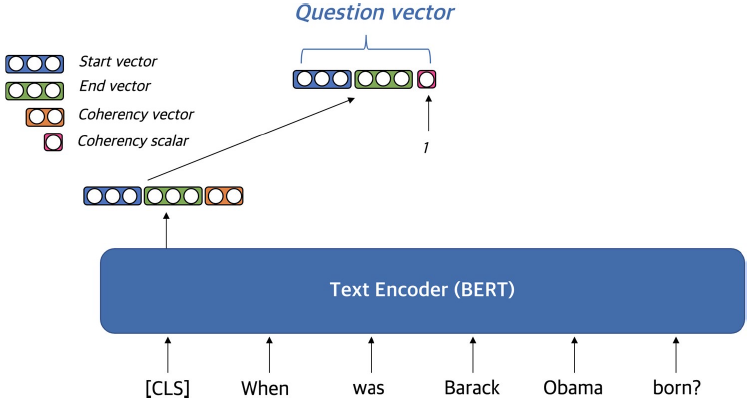
Phrase and Question Embedding
Dense vector와 sparse vector를 모두 사용하여 phrase (and question) embedding
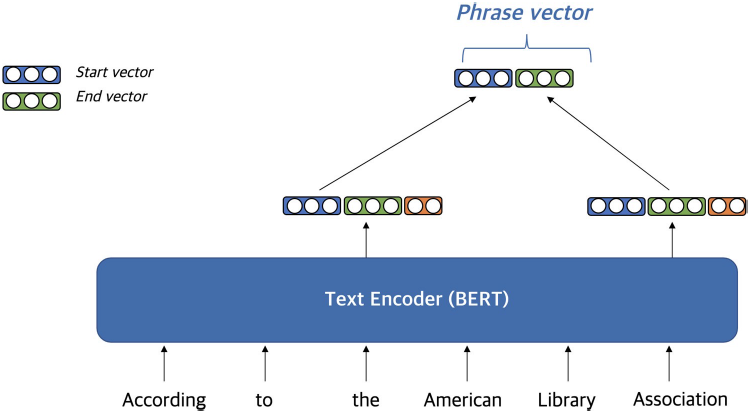
Dense representation
Dense vector를 만드는 방법
Pre-trained LM (e.g. BERT)를 이용
start vector와 end vector를 재사용해서 메모리 사용량을 줄임
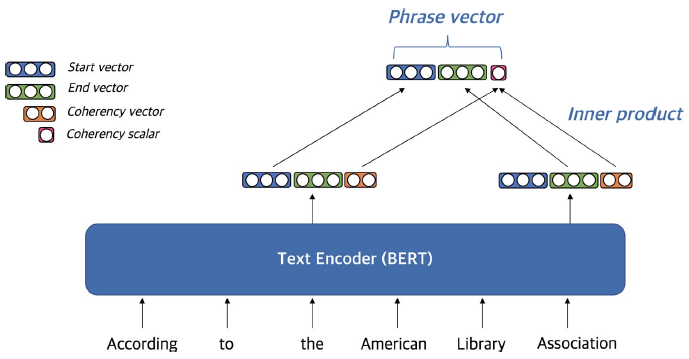
Coherency vector
phrase가 한 단위의 문장 구성 요소에 해당하는지를 나타냄
구(句)를 형성하지 않는 phrase를 걸러내기 위해 사용함
start vector와 end vector를 이용하여 계산
Question embedding
Question을 임베딩할 때는 [CLS] 토큰(BERT)을 활용
Sparse representation
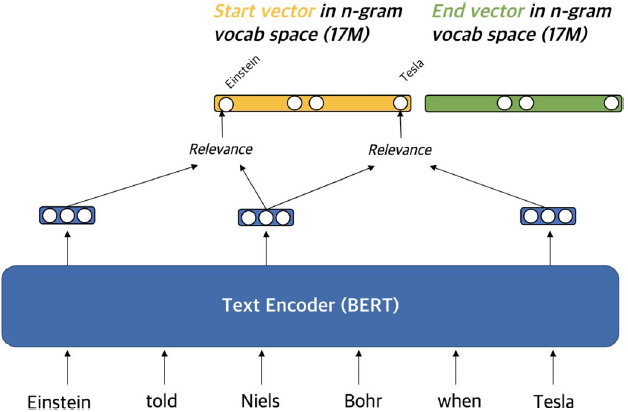
Sparse vector를 만드는 방법
문맥화된 임베딩(contextualized embedding)을 활용하여 가장 관련성이 높은 n-gram으로 sparse vector 구성
Scalability Challenge
- In Wikipedia : 60 billion개의 phrases가 존재 ⇒ storage, indexing, search의 scalability가 고려되어야 함
- Storage : pointer, filter, scalar quantization 활용 (240T storage ⇒ 1.4T storage)
- Search : FAISS를 활용해 dense vector에 대한 search를 먼저 수행 후 sparse vector로 reranking
- In Wikipedia : 60 billion개의 phrases가 존재 ⇒ storage, indexing, search의 scalability가 고려되어야 함
Experiment Results & Analysis
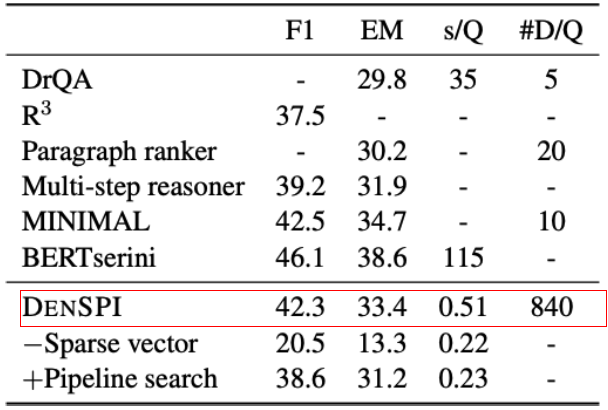
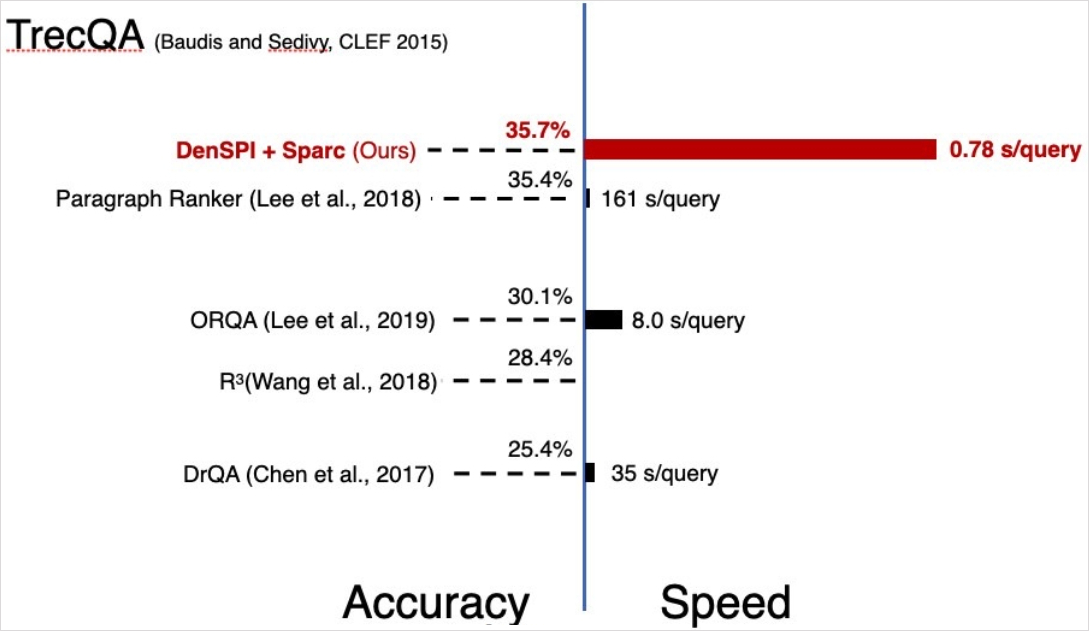
Experiment Results - SQuAD-open
SQuAD-open (Open-domain QA)
s/Q : seconds per query on CPU
#D/Q : number of documents visited per query
DrQA (Retriever-reader)보다 +3.6% 성능 / 68x 빠른 inference speed(less than 1s)
Limitation in Phrase Retrieval Approach

Decomposability gap
(기존) question, passage, answer가 모두 함께 encoding
(Phrase retrieval) Question과 passage/answer이 각각 encoding → question과 passage사이 attention 정보 x
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (Product Serving) Cloud (0) | 2023.09.20 |
|---|---|
| (AI 서비스 개발) 내가 만든 AI 모델은 합법일까, 불법일까 (1) | 2023.09.19 |
| (MRC) Closed-book QA with T5 (0) | 2023.09.16 |
| (MRC) Reducing Training Bias (0) | 2023.09.15 |
| (MRC) Linking MRC and Retrieval (0) | 2023.09.14 |


