
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- GPT
- AI Math
- 현대자동차
- 딥러닝
- nlp
- RNN
- 데이터 시각화
- Optimization
- passage retrieval
- AI 경진대회
- Bert
- dataset
- N2N
- mrc
- word2vec
- ODQA
- 데이터 구축
- matplotlib
- pyTorch
- Attention
- Self-attention
- Ai
- Data Viz
- 2023 현대차·기아 CTO AI 경진대회
- N21
- 기아
- KLUE
- Bart
- Transformer
- seaborn
- Today
- Total
쉬엄쉬엄블로그
(MRC) Closed-book QA with T5 본문
이 색깔은 주석이라 무시하셔도 됩니다.
Closed-book QA with T5
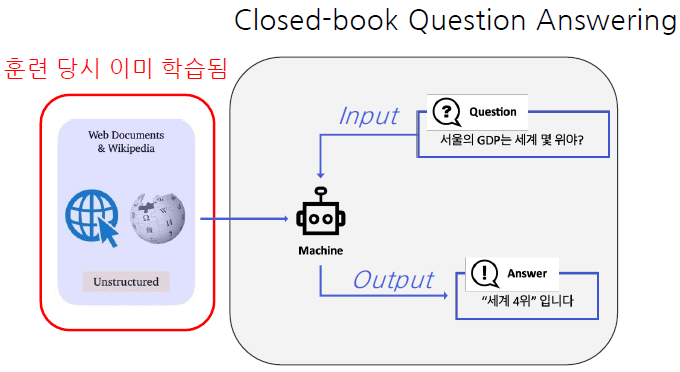
Closed-book Question Answering
- Current approaches of builiding QA system

Idea of Closed-book Question Answering
모델이 이미 사전학습으로 대량의 지식을 학습했다면, 사전학습 언어모델 자체가 이미 하나의 knowledge storage라고 볼 수 있지 않을까? ⇒ 굳이 다른 곳에서 지식을 가져와야할 필요가 없지 않을까?

모델 안에 모든 정보가 포함되어 있어야 함
대량의 지식을 사전학습한 언어 모델이 하나의 knowledge storage인 것
Zero-shot QA performance of GPT-2
사전학습 시 전혀 본적 없는 Natural Questions 데이터셋에도 어느 정도 대답이 가능함

Open-book QA vs. Closed-book QA

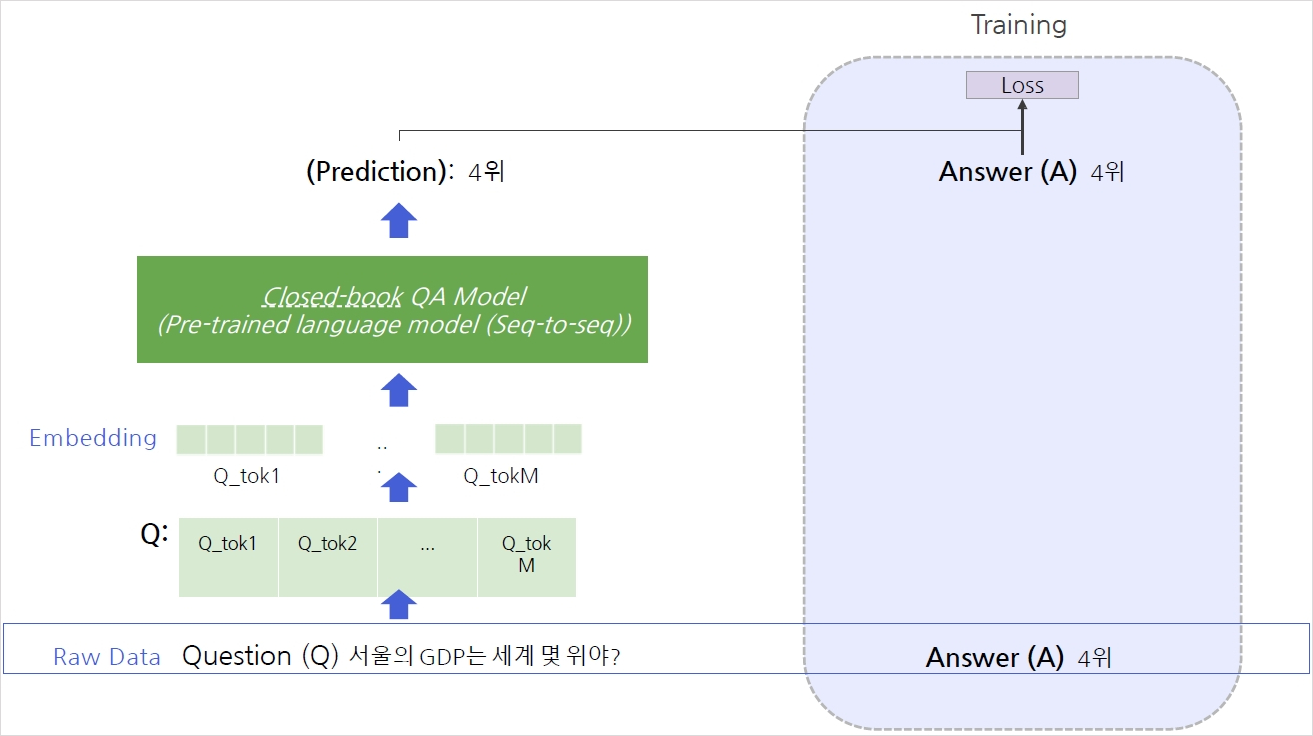
Text-to-Text Format
Closed-book QA as Text-to-Text Format
Closed-Book QA에 사용되는 방법은 Generation-based MRC와 유사함(3강)
→ 단, 입력에 지문(context)가 없이 질문만 들어간다는 것이 차이점
사전학습된 언어 모델은 BART와 같은 seq-to-seq 형태의 Transformer 모델을 사용함
Text-to-Text format에서는 각 입력값(질문)과 출력값(답변)에 대한 설명을 맨 앞에 추가함
Text-to-Text Format
Text-to-Text problem : input으로 text를 받아서 output으로 새로운 text를 생성하는 문제
다양한 text processing problem ⇒ Text-to-Text 문제로 변형

Text-to-Text Format Example 1
Task-specific prefix를 추가 ⇒ 특정 task에 알맞은 ouptut text를 생성하도록
Ex 1) Machine translation : prefix = translate A to B (A: source language / B: target language)

Text-to-Text Format Example 2
Ex2) Text classification (MNLI)
MNLI : 두 개의 sentence(premise, hypothesis)가 주어지고, 이 둘의 관계를 예측하는 task (neutral, contradiction, entailment)
Input : “mnli hypothesis: <sent1> premise: <sent2>”
Output : “neutral” or “contradiction” or “entailment”

Model Overview
- BART와 유사하고 BART와 같은 모델의 상위호환 방법이라 볼 수 있음
- BART 같은 생성 모델을 활용하여 text-to-text format으로 학습시킨다면 BART도 마찬가지로 성능이 잘 나올 수 있을 것
T5
Text-to-Text format 이라는 형태로 데이터의 입출력을 만들어 거의 모든 자연어처리 문제를 해결하도록 학습된 seq-to-seq 형태의 Transformer 모델
Pre-training T5
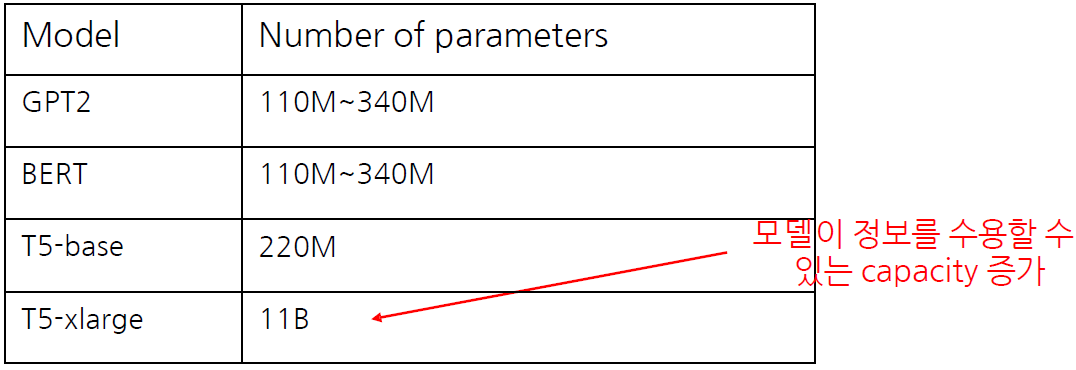
다양한 모델 구조, 사전학습 목표, 사전학습용 데이터, Fine-tuning 방법 등을 체계적으로 실험함
가장 성능이 좋은 방식들을 선택하여 방대한 규모의 모델을 학습시킴

Using T5 for Closed-book QA
Fine-tuning T5
미리 학습된 pre-trained T5를 활용
Fine-tuning : MRC 데이터셋 (TriviaQA, WebQuestions, Natural Questions)의 QA pair를 활용

MRC 데이터셋에 제공되는 supporting document는 무시
Input : Task-specific prefix 추가 ⇒ “trivia question: <question>”
Natural Questions와 같이 답이 여러개인 경우 target ⇒ “answer: <answer1> answer:<answer2>”

Experiment Results & Analysis
Experiment Setting
- Dataset
- Open-domain QA 데이터셋 또는 MRC 데이터셋에서 지문을 제거하고 질문과 답변만 남긴 데이터셋을 활용
- Salient Span Masking
- 고유 명사, 날짜 등 의미를 갖는 단위에 속하는 토큰 범위를 마스킹한 뒤 학습
- Pre-trained 체크포인트에서 추가로 pre-training함
- Fine-tuning
- Pre-trained T5 체크포인트를 Open-domain QA 학습 데이터셋으로 추가 학습
- Dataset
Experiment Examples
T5를 이용한 Closed-book Question Answering 예시

답이 틀릴 순 있지만 어느정도 질문을 이해한다는 것을 확인할 수 있음
Quantitative Examples
대부분의 Open-book 스타일 모델 (문서 검색 후 기계 독해)보다 뛰어난 성능을 보여줌
모델 크기가 커질수록 성능이 증가함
Sailent Span Masking(SSM)이 성능을 크게 끌어올림

False negatives
Exact match 기준으로 오답으로 채점된 결과를 사람이 평가한 결과 오답이 아닌 경우
Phrasing Mismatch : 정답에 대한 표현이 다른 경우
Incomplete Annotation : 정답이 여러 개일 수 있으나 하나만 정답으로 처리되는 경우
Unanswerable : 질문을 한 시간이나 문맥에 따라서 정답이 달라지는 경우

- 62%정도는 실제로 틀린 정답이지만 나머지는 틀렸다고 보기 힘든 정답이었음
Limitations
- Closed-book QA의 한계점 및 앞으로의 개선 방향
- 모델의 크기가 커서 계산량이 많고 속도가 느림
- 더 효율적인 모델 필요
- 모델이 어떤 데이터로 답을 내는지 알 수 없음
- 결과의 해석 가능성(interpretability)을 높이는 연구 필요
- 모델이 참조하는 지식을 추가하거나 제거하기 어려움
- 모델의 크기가 커서 계산량이 많고 속도가 느림
- Closed-book QA의 한계점 및 앞으로의 개선 방향
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (AI 서비스 개발) 내가 만든 AI 모델은 합법일까, 불법일까 (1) | 2023.09.19 |
|---|---|
| (MRC) QA with Phrase Retrieval (0) | 2023.09.18 |
| (MRC) Reducing Training Bias (0) | 2023.09.15 |
| (MRC) Linking MRC and Retrieval (0) | 2023.09.14 |
| (MRC) Passage Retrieval-Scaling Up (0) | 2023.09.13 |


