
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- N21
- Data Viz
- Transformer
- AI Math
- RNN
- word2vec
- N2N
- Optimization
- GPT
- Bert
- matplotlib
- passage retrieval
- Self-attention
- 현대자동차
- dataset
- Attention
- 딥러닝
- 기아
- AI 경진대회
- pyTorch
- Ai
- KLUE
- seaborn
- 데이터 시각화
- nlp
- 데이터 구축
- 2023 현대차·기아 CTO AI 경진대회
- ODQA
- mrc
- Bart
- Today
- Total
쉬엄쉬엄블로그
(MRC) Passage Retrieval-Dense Embedding 본문
이 색깔은 주석이라 무시하셔도 됩니다.
Passage Retrieval-Dense Embedding
Dense Embedding
Introduction to Dense Embedding
Passage Embedding
구절(Passage)을 벡터로 변환하는 것

Sparse Embedding
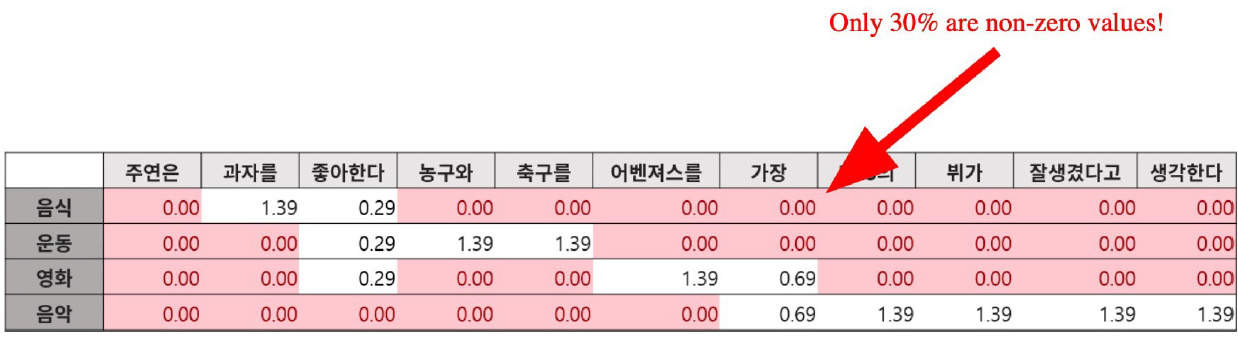
TF-IDF 벡터는 Sparse하다.
0이 0이 아닌 값보다 많다

Limitations of sparse embedding
차원의 수가 매우 크다 → compressed format으로 극복 가능
유사성을 고려하지 못한다
Dense Embedding이란?
Complementray to sparse representations by design
더 작은 차원의 고밀도 벡터 (length = 50-1000)
각 차원이 특정 term에 대응되지 않음
대부분의 요소가 non-zero값

Retrieval: Sparse vs Dense

sparse는 항상 dense에 비해 차원이 크기 때문에 활용할 수 있는 알고리즘에 한계가 있지만 dense는 다양한 알고리즘을 활용할 수 있음

sparse embedding도 장점이 있기 때문에 현업에서 많이 쓰이지만 sparse embedding 하나만으로는 많은 것을 하기 쉽지 않음
그래서 일반적으로 sparse embedding + dense embedding을 사용하거나 dense embedding 만으로 retrieval을 구축하는 것을 추천
Overview of Passage Retrieval with Dense Embedding



Training Dense Encoder
What can be Dense Encoder?
BERT와 같은 Pre-trained language model(PLM)이 자주 사용
그 외 다양한 neural network 구조도 가능
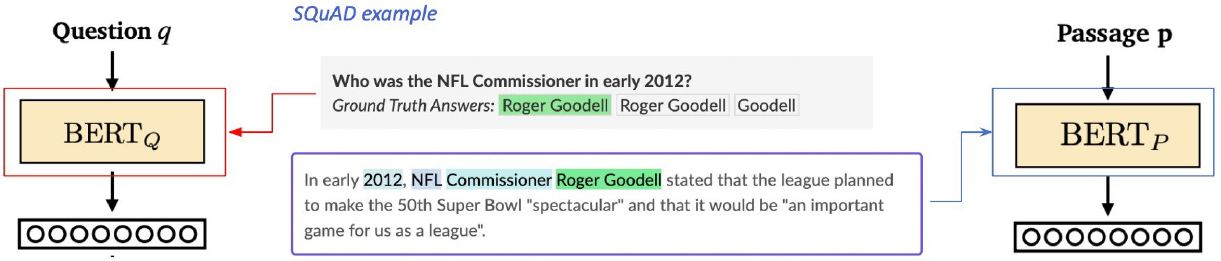
BERT as dense encoder → [CLS] token의 output 사용

Dense Encoder 구조

Dense Encoder 학습 목표와 학습 데이터
학습 목표 : 연관된 question과 passage dense embedding 간의 거리를 좁히는 것 (또는 inner product를 높이는 것). 즉 higher similarity.
Challenge : 연관된 question / passage를 어떻게 찾을 것인가?
→ 기존 MRC 데이터셋을 활용
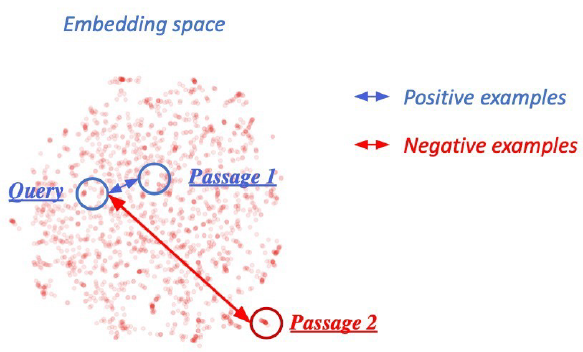
Dense Encoder 학습 목표와 학습 데이터 - Negative Sampling
연관된 question과 passage 간의 dense embedding 거리를 좁히는 것 (higher similarity) ⇒ positive
연관 되지 않은 question과 passage간의 embedding 거리는 멀어야 함 ⇒ Negative
- Choosing negative examples
- Corpus 내에서 랜덤하게 뽑기
- 좀 더 헷갈리는 negative 샘플들 뽑기
(ex. 높은 TF-IDF 스코어를 가지지만 답을 포함하지 않는 샘플)
Objective function
Positive passage에 대한 negative log likelihood(NLL) loss 사용

Positive Score / Positive + Negative Score
Evaluation Metric for Dense Encoder
Top-k retrieval accuracy : retrieve된 passage 중에 답을 포함하는 passage의 비율

MRC 관련된 evaluation metric으로는 retrieve된 passage 중에서 답을 포함하는 passage의 비율을 볼 수 있음
여기서 답은 최종 MRC 답변
MRC 모델의 extractive 형태를 택한다면 passage 내에 답이 없을 때 답을 낼 수 없기 때문에 upper bound 라고 볼 수 있음
Passage Retrieval with Dense Encoder
From dense encoding to retrieval
Inference : Passage와 query를 각각 embedding한 후, query로부터 가까운 순서대로 passage의 순위를 매김

From retrieval to open-domain question answering
Retrieval를 통해 찾아낸 Passage를 활용, MRC(Machine Reading Comprehension) 모델로 답을 찾음

How to make better dense encoding
- 학습 방법 개선 (e.g. DPR)
- 인코더 모델 개선 (BERT보다 큰, 정확한 Pretrained 모델)
- 데이터 개선 (더 많은 데이터, 전처리, 등)
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (MRC) Linking MRC and Retrieval (0) | 2023.09.14 |
|---|---|
| (MRC) Passage Retrieval-Scaling Up (0) | 2023.09.13 |
| (MRC) Passage Retrieval-Sparse Embedding (0) | 2023.09.11 |
| (MRC) Generation-based MRC (0) | 2023.09.08 |
| (MRC) Extraction-based MRC (1) | 2023.09.07 |



