
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- N21
- Bart
- RNN
- Transformer
- Optimization
- GPT
- passage retrieval
- pyTorch
- seaborn
- KLUE
- Bert
- Attention
- 딥러닝
- mrc
- AI 경진대회
- word2vec
- N2N
- 2023 현대차·기아 CTO AI 경진대회
- 데이터 시각화
- 현대자동차
- 데이터 구축
- matplotlib
- Ai
- dataset
- 기아
- Data Viz
- AI Math
- ODQA
- Self-attention
- nlp
- Today
- Total
쉬엄쉬엄블로그
(MRC) Extraction-based MRC 본문
이 색깔은 주석이라 무시하셔도 됩니다.
Extraction-based MRC
Extraction-based MRC 문제 정의
질문(question)의 답변(answer)이 항상 주어진 지문(context)내에 span으로 존재
e.g. SQuAD, KorQuAD, NewsQA, Natural Questions, etc.

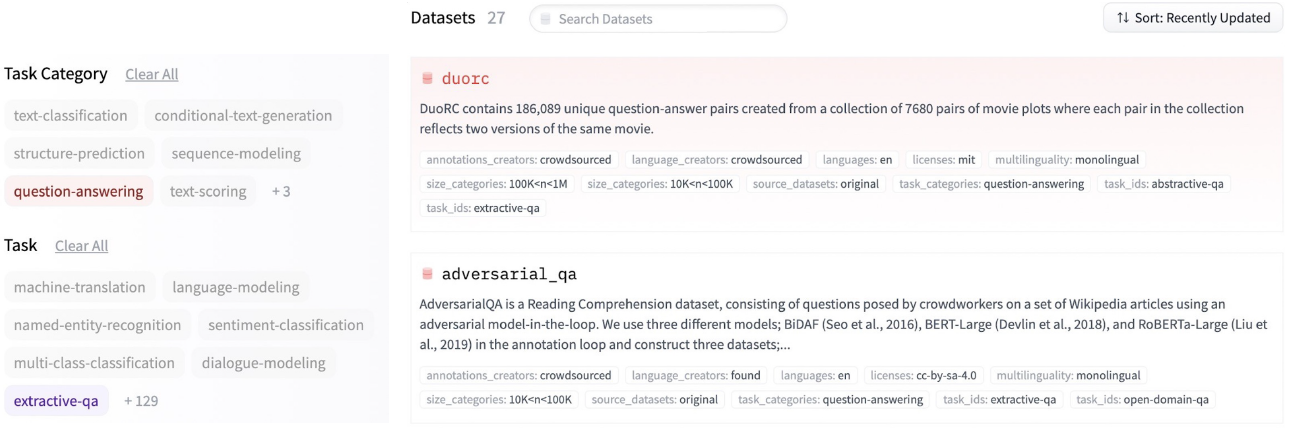
Extraction-based MRC datasets in Hugging Face datasets
Extraction-based MRC 평가 방법

Exact Match (EM) Score
- 예측값과 정답이 캐릭터 단위로 완전히 똑같은 경우에만 1점 부여
- 하나라도 다른 경우 0점
F1 Score
예측값과 정답의 overlap을 비율로 계산
0점과 1점사이의 부분점수를 받을 수 있음

예제

Extraction-based MRC Overview
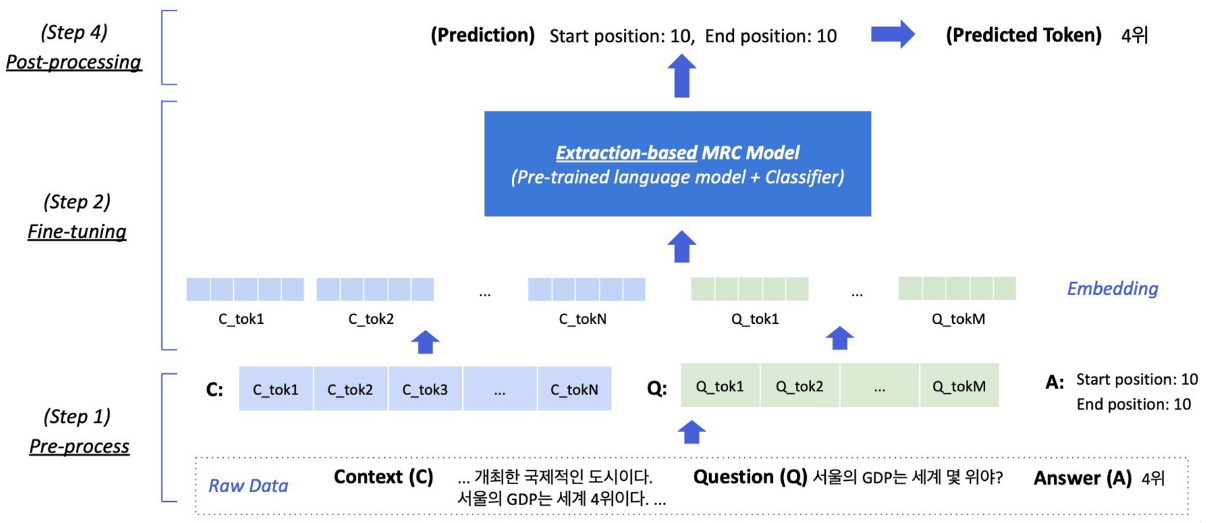
Pre-processing
입력 예시

Tokenization
- 텍스트를 작은 단위(Token)로 나누는 것
- 띄어쓰기 기준, 형태소, subword 등 여러 단위 토큰 기준이 사용됨
- 최근엔 Out-Of-Vocabulary(OOV) 문제를 해결해주고 정보학적으로 이점을 가진 Byte Pair Encoding(BPE)을 주로 사용함
- 본강에선 BPE 방법론 중 하나인 WordPiece Tokenizer를 사용
- WordPiece Tokenizer 사용 예시
- “미국 군대 내 두번째로 높은 직위는 무엇인가?”
- [’미국’, ‘군대’, ‘내’, ‘두번째’, ‘##로’, ‘높은’, ‘직’, ‘##위는’, ‘무엇인가’, ‘?’]
- 텍스트를 작은 단위(Token)로 나누는 것
Special Tokens


- [CLS], [SEP], [PAD], [UNK], …
Attention Mask
입력 시퀀스 중에서 attention을 연산할 때 무시할 토큰을 표시
0은 무시, 1은 연산에 포함
보통 [PAD]와 같은 의미가 없는 특수토큰을 무시하기 위해 사용

Token Type IDs
입력이 2개이상의 시퀀스일 때 (예: 질문 & 지문), 각각에게 ID를 부여하여 모델이 구분해서 해석하도록 유도

모델 출력값
정답은 문서내 존재하는 연속된 단어토큰(span)이므로, span의 시작과 끝 위치를 알면 정답을 맞출 수 있음
Extraction-based에선 답안을 생성하기 보다, 시작위치와 끝위치를 예측하도록 학습함.
즉 Token Classification 문제로 치환
정답이 부분적으로 나뉘어져서 정확히 일치하는 부분이 없을 수도 있지만 최소한으로 포함하는 단어를 정답으로 사용한다고 보면 됨
Fine-tuning
Extraction-based MRC Overview

Fine-tuning BERT

Post-processing
- 불가능한 답 제거하기
- 다음과 같은 경우 candidate list에서 제거
- End position이 start position보다 앞에 있는 경우 (e.g. start = 90, end = 80)
- 예측한 위치가 context를 벗어난 경우 (e.g. question 위치쪽에 답이 나온 경우)
- 미리 설정한 max_answer_length 보다 길이가 긴 경우
- 다음과 같은 경우 candidate list에서 제거
- 최적의 답안 찾기
- start/end position prediction에서 score(logits)가 가장 높은 N개를 각각 찾는다.
- 불가능한 start/end 조합을 제거한다.
- 가능한 조합들을 score의 합이 큰 순서대로 정렬한다.
- score가 가장 큰 조합을 최종 예측으로 선정한다.
- tok-k가 필요한 경우 차례대로 내보낸다.
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (MRC) Passage Retrieval-Sparse Embedding (0) | 2023.09.11 |
|---|---|
| (MRC) Generation-based MRC (0) | 2023.09.08 |
| (MRC) MRC Intro (0) | 2023.09.06 |
| (데이터 제작) 관계 추출 데이터 구축 실습 (0) | 2023.09.05 |
| (데이터 제작) 관계 추출 관련 논문 읽기 (0) | 2023.09.04 |



