
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Optimization
- pyTorch
- ODQA
- 데이터 구축
- 기아
- Transformer
- RNN
- passage retrieval
- Bert
- Self-attention
- word2vec
- N2N
- dataset
- 현대자동차
- AI 경진대회
- Bart
- 데이터 시각화
- AI Math
- 딥러닝
- nlp
- N21
- Ai
- 2023 현대차·기아 CTO AI 경진대회
- KLUE
- mrc
- Data Viz
- Attention
- seaborn
- GPT
- matplotlib
- Today
- Total
쉬엄쉬엄블로그
(KLUE) BERT 언어모델 소개 본문
이 색깔은 주석이라 무시하셔도 됩니다.
한국어 언어 모델 학습 및 다중 과제 튜닝
BERT 언어모델
BERT 모델 소개

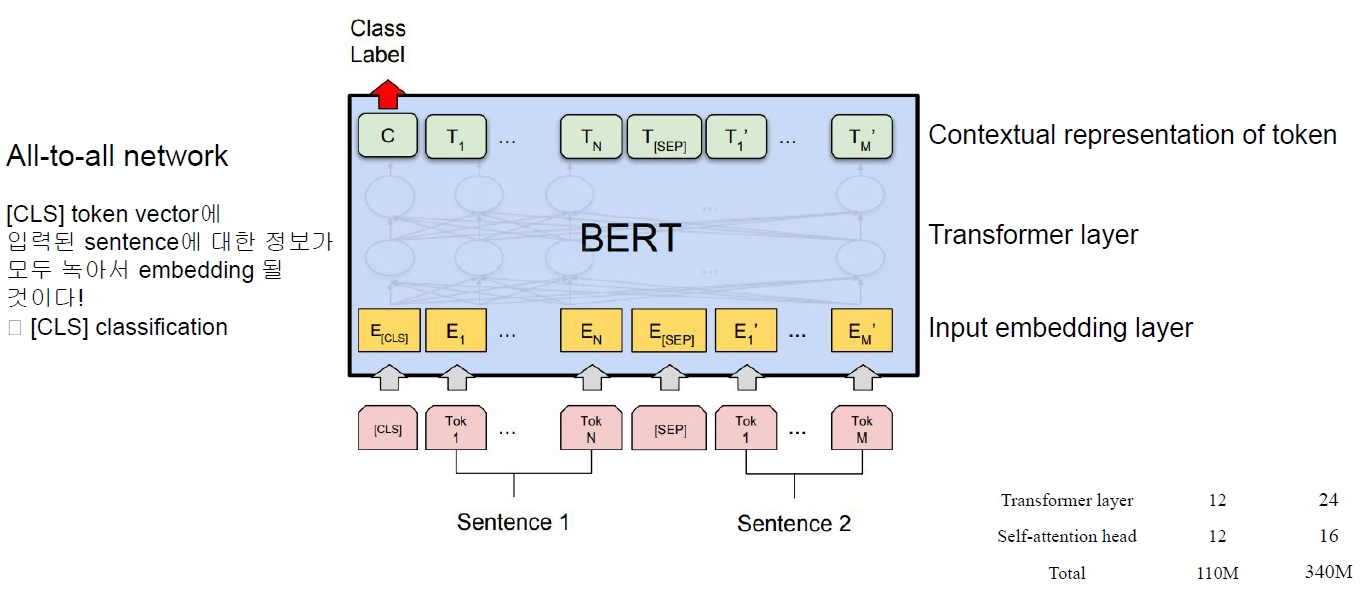
- 트랜스포머 모델은 인코더와 디코더가 하나로 합쳐져있는 구성을 가짐

- BERT는 self attention 즉, 트랜스포머를 사용한 모델
- 입력된 정보를 다시 입력된 정보로 표현하기 위해 학습됨
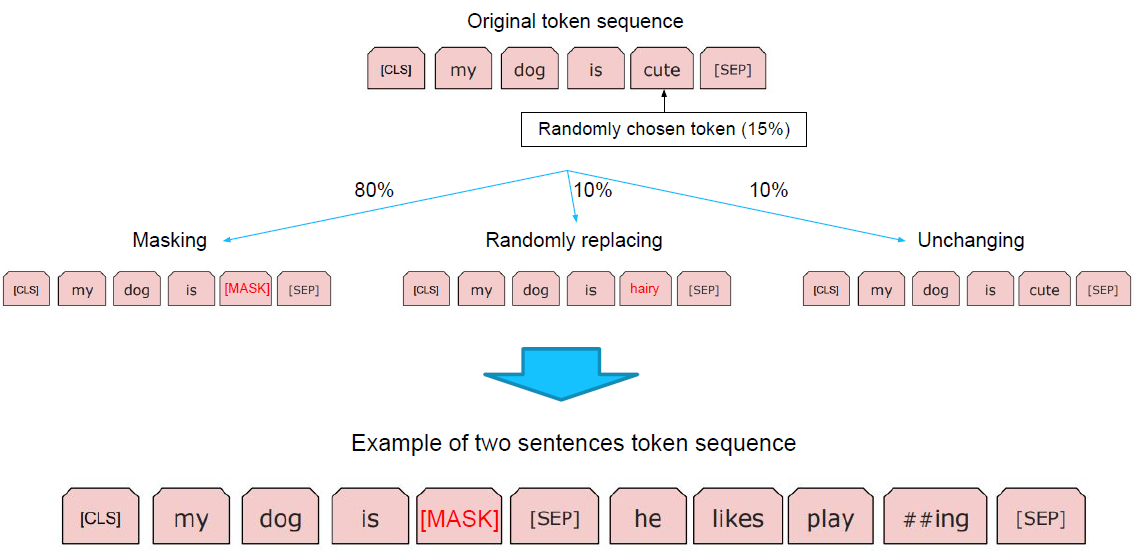
- 그런데 그냥 원본을 복원하는 것이 아니라 masked된 단어를 맞추도록 학습함
- 더 어렵게 만든 문제를 해결하도록 만들어서 언어를 학습하도록 만듬

* GPT-2는 원본 이미지를 특정한 sequence를 가지고 잘라낸 후 그 다음을 예측하도록 학습함*
모델 구조도
학습 코퍼스 데이터
- BooksCorpus (800M words)
- English Wikipedia (2,500M words without lists, tables and headers)
- 30,000 token vocabulary
데이터의 tokenizing
WordPiece tokenizing
He likes playing → He likes play ##ing
입력 문장을 tokenizing하고, 그 token들로 ‘token sequence’를 만들어 학습에 사용
2개의 token sequence가 학습에 사용

Masked Langauge Model
NLP 실험

위 데이터들을 통해 성능 평가 지표를 만듬

BERT 모델의 응용
감성 분석
입력된 문장의 대해서 이 문장이 긍정이냐 부정이냐를 분류하는 task

관계 추출
문장 내에 존재하는 지식 정보를 추출하는 task
관계 추출의 대상이 되는 존재를 entity라고 함
ex) ‘이순신은 조선 중기의 무신이다.’ 에서 이순신의 직업을 물었다면 ‘이순신’ 과 ‘무신’ 이 entity가 됨*

의미 비교
두 문장이 의미적으로 같냐 다르냐를 분류하는 task

데이터가 너무 쉽기 때문에 현업에서 쓸 수 없음
개체명 분석

기계 독해

- task에 맞춰서 tokenizer를 정의하여 사용하면 성능 개선이 가능
한국어 BERT 모델
ETRI KoBERT의 tokenizing
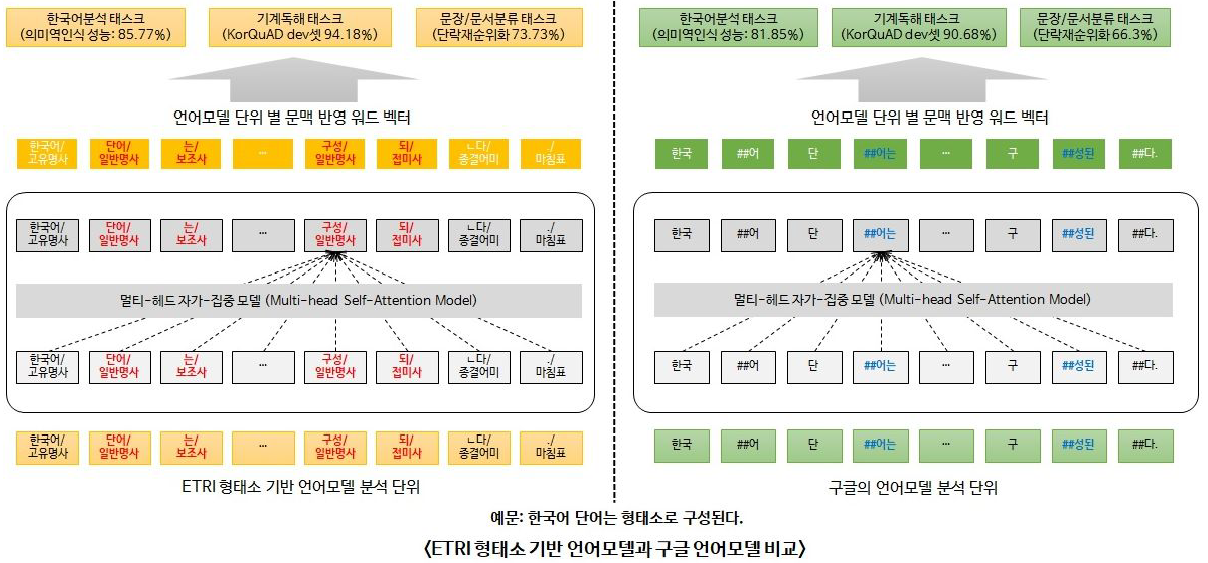
한국어 tokenizing에 따른 성능 비교 (https://arxiv.org/abs2010.02534)

- 형태소 분석을 먼저하고 wordpiece를 적용한 것(Morpheme-aware Subword)이 성능이 가장 좋았음
Advanced BERT model
KBQA에서 가장 중요한 entity 정보가 기존 BERT에서는 무시
Entity linking을 통한 주요 entity 추출 및 entity tag 부착
Entity embedding layer의 추가
형태소 분석을 통해 NNP와 entity 우선 chunking masking


학습 데이터 : 2019년 6월 20일 Wiki dump (약 4,700만 어절)
Batch : 128
Sequence length : 512
Training steps : 300,000 (대략 10 epochs)

entity embedding layer를 추가하여 wiki(약 600MB) 데이터를 사용했을 때 성능이 훨씬 향상됨
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (KLUE) BERT 언어모델 기반의 단일 문장 분류 (0) | 2023.08.17 |
|---|---|
| (KLUE) BERT Pre-Training (0) | 2023.08.16 |
| (KLUE) 자연어의 전처리 (0) | 2023.08.15 |
| (KLUE) 인공지능과 자연어 처리 (0) | 2023.08.11 |
| (AI 서비스 개발 기초) MLflow (0) | 2023.08.10 |



