
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- pyTorch
- 현대자동차
- 데이터 구축
- Optimization
- Bart
- N21
- RNN
- seaborn
- 딥러닝
- Attention
- Ai
- passage retrieval
- GPT
- Self-attention
- matplotlib
- Data Viz
- Transformer
- 2023 현대차·기아 CTO AI 경진대회
- KLUE
- nlp
- 데이터 시각화
- AI Math
- 기아
- mrc
- N2N
- dataset
- ODQA
- word2vec
- AI 경진대회
- Bert
Archives
- Today
- Total
쉬엄쉬엄블로그
(KLUE) BERT 언어모델 기반의 단일 문장 분류 본문
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
한국어 언어 모델 학습 및 다중 과제 튜닝
BERT 언어모델 기반의 단일 문장 분류
KLUE 데이터셋
- 한국어 자연어 이해 벤치마크(Korean Langauge Understanding Evaluation, KLUE)
- 자연어 task 유형
- 문장 분류, 관계 추출 → 단일 문장 분류 task (5강)
- 문장 유사도 → 문장 임베딩 벡터의 유사도 (e.g. [CLS])
- 자연어 추론 → 두 문장 관계 분류 task (6강)
- 개체명 인식, 품사 태깅, 질의 응답 → 문장 토큰 분류 task (7강)
- 목적형 대화 → 김성동님, DST 강의
- 의존 구문 분석
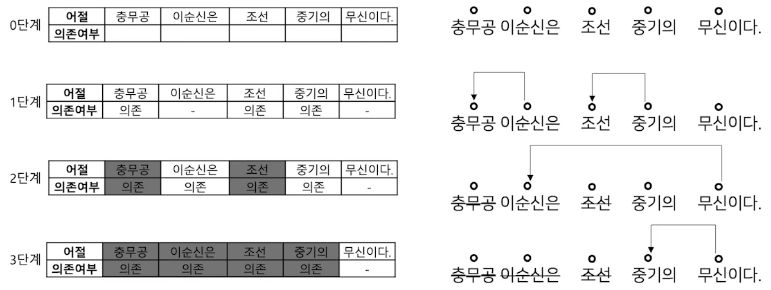
의존 구문 분석
단어들 사이의 관계를 분석하는 task

특징
- 지배소 : 의미의 중심이 되는 요소
- 의존소 : 지배소가 갖는 의미를 보완해주는 요소 (수식)
- 어순과 생략이 자유로운 한국어와 같은 언어에서 주로 연구된다.
분류 규칙
- 지배소는 후위언어이다. 즉 지배소는 항상 의존소보다 뒤에 위치한다.
- 각 의존소의 지배소는 하나이다.
- 교차 의존 구조는 없다.
분류 방법
Sequence labeling 방식으로 처리 단계를 나눈다.
앞 어절에 의존소가 없고 다음 어절이 지배소인 어절을 삭제하며 의존 관계를 만든다.
어디에 써요?

- 복잡한 자연어 형태를 그래프로 구조화해서 표현 가능!
- 각 대상에 대한 정보 추출이 가능!
- 구름그림 → 새털구름을 그린 것 → 내가 그린 것
- “나”는 “구름그림”을 그렸다.
- “구름 그림”은 “새털구름”을 그린 것이다.
단일 문장 분류 task 소개
문장 분류 task
- 주어진 문장이 어떤 종류의 범주에 속하는지를 구분하는 task
- 감정분석(Sentiment Analysis)
- 문장의 긍정 또는 부정 및 중립 등 성향을 분류하는 프로세스
- 문장을 작성한 사람의 느낌, 감정 등을 분석 할 수 있기 때문에 기업에서 모니터링, 고객지원, 또는 댓글에 대한 필터링 등을 자동화하는 작업에 주로 사용
- 활용 방안
- 혐오 발언 분류 : 댓글, 게임 대화 등 혐오 발언을 분류하여 조치를 취하는 용도로 활용
- 기업 모니터링 : 소셜, 리뷰 등 데이터에 대해 기업 이미지, 브랜드 선호도, 제품평가 등 긍정 또는 부정적 요인을 분석
- 주제 라벨링(Topic Labeling)
- 문장의 내용을 이해하고 적절한에 범주를 분류하는 프로세스
- 주제별로 뉴스 기사를 구성하는 등 데이터 구조화와 구성에 용이
- 활용 방안
- 대용량 문서 분류 : 대용량의 문서를 범주화
- VoC(Voice of Customer) : 고객의 피드백을 제품 가격, 개선점, 디자인 등 적절한 주제로 분류하여 데이터를 구조화
- 언어감지(Language Detection)
- 문장이 어떤 나라 언어인지를 분류하는 프로세스
- 주로 번역기에서 정확한 번역을 위해 입력 문장이 어떤 나라의 언어인지 타겟팅 하는 작업이 가능
- 활용 방안
- 번역기 : 번역할 문장에 대해 적절한 언어를 감지함
- 데이터 필터링 : 타겟 언어 이외 데이터는 필터링
- 의도 분류(Intent Classification)
- 문장이 가진 의도를 분류하는 프로세스
- 입력 문장이 질문, 불만, 명령 등 다양한 의도를 가질 수 있기 때문에 적절한 피드백을 줄 수 있는 곳으로 라우팅 작업이 가능
- 활용 방안
- 챗봇 : 문장의 의도인 질문, 명령, 거절 등을 분석하고 적절한 답변을 주기 위해 활용
- 감정분석(Sentiment Analysis)
문장 분류를 위한 데이터
Kor_hate

- 혐오 표현에 대한 데이터
- 특정 개인 또는 집단에 대한 공격적 문장
- 무례, 공격적이거나 비꼬는 문장
- 부정적이지 않은 문장
Kor-sarcasm

- 비꼬지 않은 표현의 문장
- 직설적으로 욕설하는 것은 비꼬지 않은 표현의 문장임
- 비꼬는 표현의 문장
- 비꼬지 않은 표현의 문장
Kor_sae

- 예/아니오로 답변 가능한 질문
- 대안 선택을 묻는 질문
- Wh- 질문 (who, what, where, when, when, why, how)
- 금지 명령
- 요구 명령
- 강한 요구 명령
Kor_3i4k
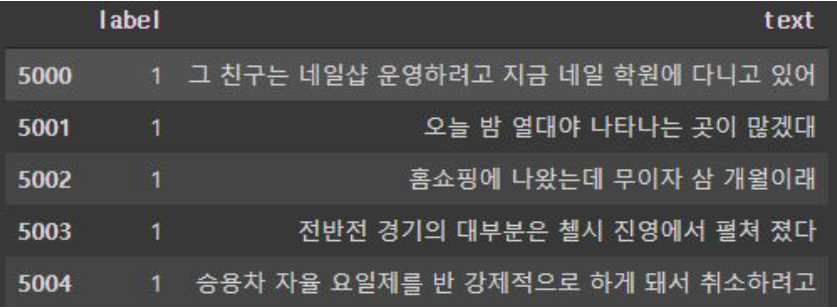
- 단어 또는 문장 조각
- 평서문
- 질문
- 명령문
- 수사적 질문
- 수사적 명령문
- 억양에 의존하는 의도
단일 문장 분류 모델 학습
모델 구조도
BERT의 [CLS] token의 vector를 classification하는 Dense layer 사용

학습 과정
- 주요 매개변수
- input_ids : sequence token을 입력
- attention_mask : [0,1]로 구성된 마스크이며 패딩 토큰을 구분
- token_type_ids : [0,1]로 구성되었으며 입력의 첫 문장과 두 번째 문장 구분
- position_ids : 각 입력 시퀀스의 임베딩 인덱스
- inputs_embeds : input_ids 대신 직접 임베딩 표현을 할당
- labels : loss 계산을 위한 레이블
- Next_sentence_label : 다음 문장 예측 loss 계산을 위한 레이블

huggingface의 trainer를 pytorch로 구현한 코드
# native training using torch model = BertForSequenceClassification.from_pretrained(MODEL_NAME) model.to(device) model.train() train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) optim = AdamW(model.parameters(), lr=5e-5) for epoch in range(3): for batch in train_loader: optim.zero_grad() input_ids = batch['input_ids'].to(device) attention_mask = batch['attention_mask'].to(device) labels = batch['labels'].to(device) outputs = model(input_ids, attention_mask=attention_mask, labels=labels) loss = outputs[0] loss.backward() optim.step()
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (KLUE) GPT 언어 모델 (0) | 2023.08.22 |
|---|---|
| (KLUE) BERT 언어모델 기반의 두 문장 관계 분류 (0) | 2023.08.18 |
| (KLUE) BERT Pre-Training (0) | 2023.08.16 |
| (KLUE) BERT 언어모델 소개 (0) | 2023.08.15 |
| (KLUE) 자연어의 전처리 (0) | 2023.08.15 |
'부스트캠프 AI Tech 4기' Related Articles
more




Comments