
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- pyTorch
- Data Viz
- nlp
- Optimization
- word2vec
- Ai
- GPT
- N2N
- Transformer
- 데이터 시각화
- matplotlib
- Bart
- AI 경진대회
- KLUE
- Self-attention
- 기아
- 2023 현대차·기아 CTO AI 경진대회
- 현대자동차
- 데이터 구축
- AI Math
- RNN
- N21
- seaborn
- dataset
- mrc
- Attention
- Bert
- ODQA
- 딥러닝
- passage retrieval
- Today
- Total
쉬엄쉬엄블로그
(KLUE) 인공지능과 자연어 처리 본문
이 색깔은 주석이라 무시하셔도 됩니다.
한국어 언어 모델 학습 및 다중 과제 튜닝
인공지능과 자연어처리
자연어처리 소개





자연어처리의 응용분야



- 컴퓨터는 자연어(텍스트)를 이해할 수 있는 능력이 없기 때문에 컴퓨터에서 정보 처리가 이루어지려면 반드시 수학적인 형태(숫자)로 변경되어야 함

주제
자연어를 컴퓨터가 이해할 수 있게 수학적으로 어떻게 이쁘게 인코딩할 수 있는지를 살펴본다!
- 인코딩이 이쁘게 되면? 디코딩을 통해 무엇이든 할 수 있다!
자연어 단어 임베딩
특징 추출과 분류
‘분류’를 위해선 데이터를 수학적으로 표현
먼저, 분류 대상의 특징(Feature)을 파악 (Feature Extraction)


분류 대상의 특징(Feature)을 기준으로, 분류 대상을 그래프 위에 표현 가능
분류 대상들의 경계를 수학적으로 나눌 수 있음(Classification)
새로운 데이터 역시 특징을 기준으로 그래프에 표현하면, 어떤 그룹과 유사한지 파악 가능

과거에는 사람이 직접 특징(Feature)을 파악해서 분류
실제 복잡한 문제들에선 분류 대상의 특징을 사람이 파악하기 어려울 수 있음
이러한 특징을 컴퓨터가 스스로 찾고(Feature extraction), 스스로 분류(Classification)하는 것이 ‘기계학습’의 핵심

Word2Vec
자연어를 어떻게 좌표평면 위에 표현할 수 있을까?
가장 단순한 표현 방법은 one-hot encoding 방식 → Sparse representation

Word2Vec (word to vector) 알고리즘 : 자연어 (특히, 단어)의 의미를 벡터 공간에 임베딩
한 단어의 주변 단어들을 통해, 그 단어의 의미를 파악

Word2Vec 알고리즘은 주변부의 단어를 예측하는 방식으로 학습 (Skip-gram 방식)
단어에 대한 dense vector를 얻을 수 있음

예시

정리

FastText
Word2Vec의 OOV 문제를 해결하기 위해 제안됨
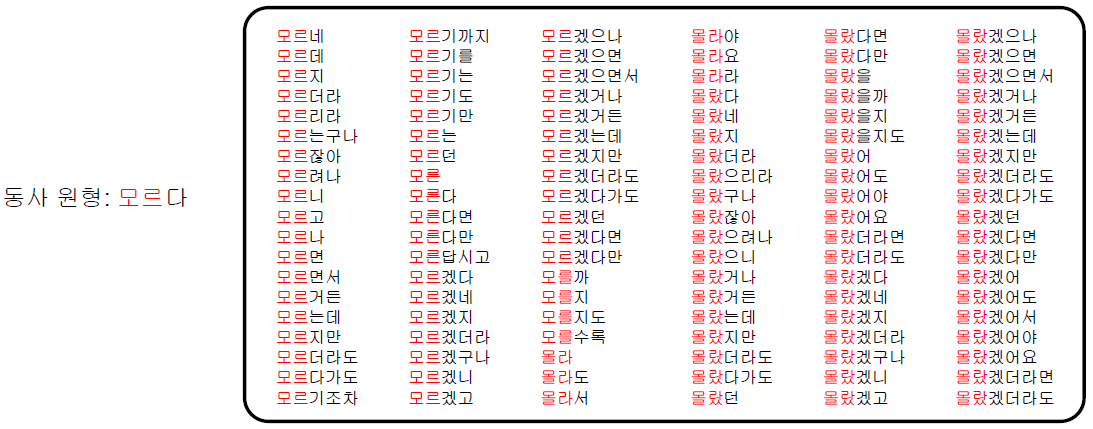
한국어는 다양한 용언 형태를 가짐
Word2Vec의 경우, 다양한 용언 표현들이 서로 독립된 vocab으로 관리
Facebook research에서 공개한 open source library
Training
- 기존의 word2vec과 유사하나, 단어를 n-gram으로 나누어 학습을 수행
- n-gram의 범위가 2-5일 때, 단어를 다음과 같이 분리하여 학습함
- “assumption” = {as, ss, su, …, ass, ssu, sum, ump, mpt, …, ption, assumption}
- 이 때, n-gram으로 나눠진 단어는 사전에 들어가지 않으며, 별도의 n-gram vector를 형성함
Testing
- 입력 단어가 vocabulary에 있을 경우, word2vec과 마찬가지로 해당 단어의 word vector를 return함
- 만약 OOV일 경우, 입력 단어의 n-gram vector들의 합산을 return함
FastText는 단어를 n-gram으로 분리를 한 후, 모든 n-gram vector를 합산한 후 평균을 통해 단어 벡터를 획득

n-gram으로 쪼개면 단어의 시작에 있던 n-gram인지 단어의 끝에 있던 n-gram인지에 대한 정보가 없어지기 때문에 <, >로 표시함
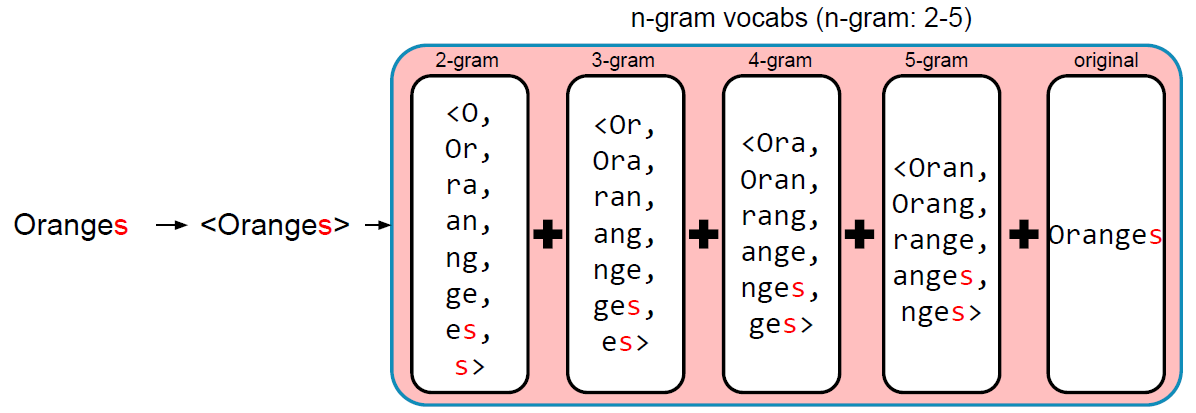
Oranges라는 OOV가 발생할 때 Word2Vec으로는 벡터 값을 얻을 수 없지만 FastText는 빨간색 글씨(s)를 제외하고는 앞서 학습했던 Orange와 동일한 bag of words 리스트를 갖게 됨
그래서 Oranges라는 단어는 OOV이지만 Orange에서 만들어졌던 n-gram과 많은 부분이 겹쳐있기 때문에 Oranges에서 벡터를 얻게 되면 Orange와 굉장히 유사한 벡터를 얻을 수 있음
FastText는 오탈자, OOV, 등장 횟수가 적은 학습 단어에 대해서 강세를 보임

- DF : 등장 횟수
단어 임베딩 방식의 한계점
Word2Vec이나 FastText와 같은 word embedding 방식은 동형어, 다의어 등에 대해선 embedding 성능이 좋지 못하다는 단점이 있음
주변 단어를 통해 학습이 이루어지기 때문에, “문맥”을 고려할 수 없음

- 주변 문맥을 이용할 수 있는 언어 임베딩 알고리즘이 필요하게 됨
딥러닝 기반의 자연어처리와 언어모델
언어모델
모델이란?
모델의 종류
- 일기예보 모델, 데이터 모델, 비즈니스 모델, 물리 모델, 분자 모델 등
모델의 특징

- 자연 법칙을 컴퓨터로 모사함으로써 시뮬레이션이 가능
- 이전 state를 기반으로 미래의 state를 예측할 수 있음 (e.g. 습도와 바람 세기 등으로 내일 날씨 예측)
- 즉, 미래의 state를 올바르게 예측하는 방식으로 모델 학습이 가능함
“자연어”의 법칙을 컴퓨터로 모사한 모델 → 언어 “모델”
주어진 단어들로부터 그 다음에 등장할 단어의 확률을 예측하는 방식으로 학습 (이전 state로 미래 state를 예측)
다음에 등장할 단어를 잘 예측하는 모델은 그 언어의 특성이 잘 반영된 모델이자, 문맥을 잘 계산하는 좋은 언어 모델

Markov 기반의 언어 모델
마코프 체인 모델 (Markov Chain Model)
초기의 언어 모델은 다음의 단어나 문장이 나올 확률을 통계와 단어의 n-gram을 기반으로 계산
딥러닝 기반의 언어모델은 해당 확률을 최대로 하도록 네트워크를 학습

Recurrent Neural Network (RNN) 기반의 언어모델
RNN은 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이룸 (directed cycle)
이전 state 정보가 다음 state를 예측하는데 사용됨으로써, 시계열 데이터 처리에 특화

마지막 출력은 앞선 단어들의 “문맥”을 고려해서 만들어진 최종 출력 vector → Context vector
출력된 context vector 값에 대해 classification layer를 붙이면 문장 분류를 위한 신경망 모델


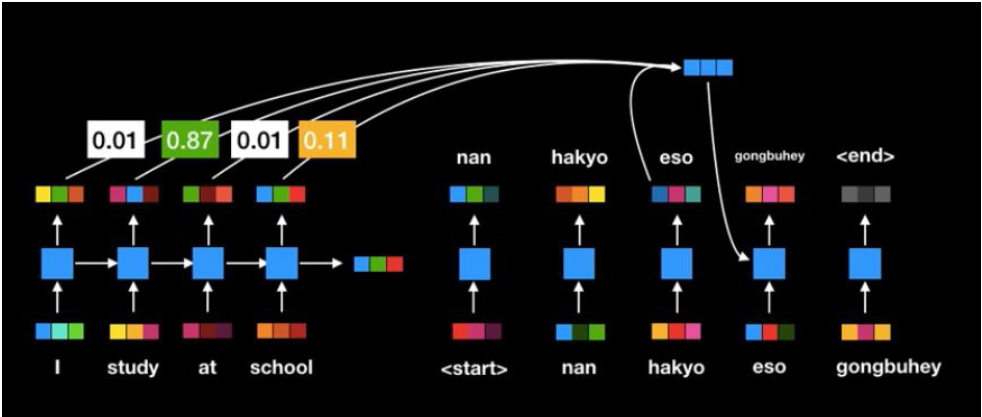
Sequence to Sequence (Seq2Seq)
Recurrent Neural Network (RNN) 기반의 Seq2Seq
Encoder layer : RNN 구조를 통해 Context vector를 획득
Decoder layer : 획득된 Context vector를 입력으로 출력을 예측


- Encoder-Decoder 방식으로 접근하면 모든 자연어처리 어플리케이션을 개발할 수 있게 됨
- ex) 음성이 입력되었을 때 Seq2Seq를 통해 음성인식기가 만들어질 수 있음
Attention
RNN 구조의 문제점
입력 Sequence의 길이가 매우 긴 경우, 처음에 나온 token에 대한 정보가 희석
고정된 context vector 사지으로 인해 긴 sequence에 대한 정보를 함축하기 어려움
모든 token이 영향을 미치니, 중요하지 않은 token도 영향을 줌

Attention 모델
인간이 정보처리를 할 때, 모든 sequence를 고려하면서 정보처리를 하는 것이 아님
인간의 정보처리와 마찬가지로, 중요한 feature는 더욱 중요하게 고려하는 것이 Attention의 모티브

문맥에 따라 동적으로 할당되는 encode의 Attention weight로 인한 dynamic context vector를 획득
기존 Seq2Seq의 encoder, decoder 성능을 비약적으로 향상시킴
- attention의 등장으로 번역 모델들이 기존 모델보다 엄청난 큰 성능 차이를 보임
하지만, 여전히 RNN이 순차적으로 연산이 이뤄짐에 따라 연산 속도가 느림

- 그래서 연결되어있는 구조를 없애고 self-attention 구조가 만들어짐
Self-Attention
Self-attention 모델

Transformer


- 기존 seq2seq 모델은 인코더 RNN 구조와 디코더 RNN 구조가 따로 존재
- 그래서 인코더의 역할은 context 벡터를 만들어내고 디코더의 역할은 그 context 벡터를 decoding하는 역할로 만들어져 있었음
- 하지만 트랜스포머 네트워크는 인코더와 디코더를 따로 분리해두는 것이 아니라 하나의 네트워크 내에 인코더와 디코더를 합쳐서 구성하게 됨
Transformer Revolution

- Transformer가 처음 제시된 이후 현재까지 굉장히 다양한 Transformer network가 제시되고 있음
다양한 언어모델

- Transformer가 다양한 언어모델이 엄청나게 만들어지는 계기가 됨
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (KLUE) BERT 언어모델 소개 (0) | 2023.08.15 |
|---|---|
| (KLUE) 자연어의 전처리 (0) | 2023.08.15 |
| (AI 서비스 개발 기초) MLflow (0) | 2023.08.10 |
| (AI 서비스 개발 기초) Docker (0) | 2023.08.09 |
| (AI 서비스 개발 기초) Linux & Shell Command (0) | 2023.08.08 |



