
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Transformer
- Bert
- 데이터 구축
- Attention
- nlp
- matplotlib
- N21
- 현대자동차
- N2N
- mrc
- ODQA
- 데이터 시각화
- Self-attention
- Bart
- 2023 현대차·기아 CTO AI 경진대회
- Ai
- AI 경진대회
- 딥러닝
- GPT
- Data Viz
- word2vec
- dataset
- pyTorch
- AI Math
- seaborn
- Optimization
- RNN
- passage retrieval
- KLUE
- 기아
Archives
- Today
- Total
쉬엄쉬엄블로그
PyTorch Troubleshooting 본문
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
공포의 단어 OOM (Out Of Memory)
- 하드웨어 환경에 따라 가장 흔하게 마주할 수 있는 에러
OOM이 해결하기 어려운 이유들…
- 왜 발생했는지 알기 어려움
- 어디서 발생했는지 알기 어려움
- Error backtracking이 이상한 곳으로 감
- 메모리의 이전 상황 파악이 어려움
우선 시도해보기 : Batch Size ↓ → GPU clean → RUN
그 외에 발생할 수 있는 문제들…
GPUUtil 사용하기
- nvidia-smi처럼 GPU의 상태를 보여주는 모듈
- Colab은 환경에서 GPU 상태를 보여주기 편함
- iter마다 메모리가 늘어나는지 확인!!

torch.cuda.empty_cache() 써보기
- 사용되지 않은 GPU상 cache를 정리
- 가용 메모리를 확보
- del과는 구분이 필요
- reset 대신 쓰기 좋은 함수
- garbage collector 실행을 강제한다고 보면 됨

- 학습 전에 이 코드를 한 번 실행해주는 것도 괜찮음
training loop에 tensor로 축적 되는 변수는 확인할 것
- tensor로 처리된 변수는 GPU 상에 메모리 사용
- 해당 변수 loop 안에 연산에 있을 때 GPU에 computational graph를 생성(메모리 잠식)
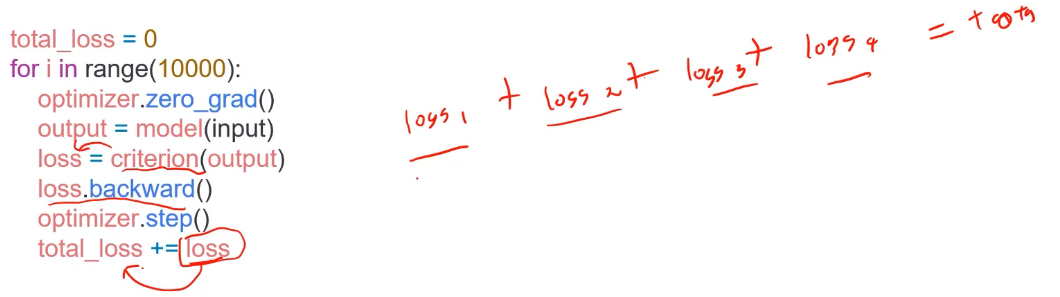

- 1-d tensor의 경우 python 기본 객체로 변환하여 처리할 것
iter_loss.item이라고 쓰면 python 기본 객체로 변환 됨
del 명령어를 적절히 사용하기
- 필요가 없어진 변수는 적절한 삭제가 필요함
- python의 메모리 배치 특성상 loop이 끝나도 메모리를 차지함
가능 batch 사이즈 실험해보기
- 학습시 OOM이 발생했다면 batch 사이즈를 1로 해서 실험해보기

torch.no_grad() 사용하기
- Inference 시점에서는
torch.no_grad()구문을 사용- train 시점과 다르게 Inference에는 gradient 계산이 필요없기 때문에
torch.no_grad()를 통해 불필요한 연산과 메모리 낭비를 막아줌
- train 시점과 다르게 Inference에는 gradient 계산이 필요없기 때문에
- backward pass로 인해 쌓이는 메모리에서 자유로움

예상치 못한 에러 메세지
- OOM 말고도 유사한 에러들이 발생
- CUDNN_STATUS_NOT_INIT이나 device-side-assert 등
- 에러 메세지에 대한 정리 글
- CUDNN_STATUS_NOT_INIT은 보통 버전 문제라고 함
- 해당 에러도 cuda와 관련하여 OOM의 일종으로 생각될 수 있으며, 적절한 코드 처리가 필요함
그 외…
- colab에서 너무 큰 사이즈는 실행하지 말 것
- linear
- CNN
- LSTM
- CNN의 대부분의 에러는 크기가 안맞아서 생기는 경우
- torchsummary 등으로 모델 구조를 보고 사이즈를 맞출 것
- tensor의 float precision을 16bit로 줄일 수도 있음
- 최후의 수단
출처 : 부스트캠프 AI Tech 4기(Naver Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| Transfer Learning + Hyper Parameter Tuning (0) | 2023.05.26 |
|---|---|
| Custom Dataset 및 Custom DataLoader 생성 (0) | 2023.05.25 |
| Hyperparameter Tuning (0) | 2023.05.23 |
| Multi-GPU - PyTorch (0) | 2023.05.22 |
| Monitoring tools for PyTorch (2) | 2023.05.20 |
'부스트캠프 AI Tech 4기' Related Articles
more



Comments