
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Bart
- Attention
- RNN
- AI Math
- dataset
- passage retrieval
- pyTorch
- 2023 현대차·기아 CTO AI 경진대회
- AI 경진대회
- Bert
- 데이터 구축
- nlp
- word2vec
- GPT
- mrc
- Data Viz
- ODQA
- 기아
- N21
- 딥러닝
- Optimization
- matplotlib
- Transformer
- Ai
- 현대자동차
- Self-attention
- N2N
- seaborn
- KLUE
- 데이터 시각화
Archives
- Today
- Total
쉬엄쉬엄블로그
Multi-GPU - PyTorch 본문
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
오늘날의 딥러닝은 엄청난 데이터와의 싸움

- 엄청난 양의 데이터를 다루고 계산하기 위해 메모리가 크고 성능이 좋은 GPU가 필요함
- 여러 개의 GPU를 통해 더 좋은 성능을 얻을 수 있음
Multi-GPU
어떻게 GPU를 다룰 것인가
개념 정리
- Single vs. Multi
- GPU vs. Node
- Node : system, 컴퓨터 1대
- Single Node Single GPU
- Single Node Mulit GPU
- 보통 multi gpu를 사용하는 환경
- Multi Node Multi GPU
- 활용이 많이 어려움
Model parallel vs Data parallel
- 다중 GPU에 학습을 분산하는 두 가지 방법
- 모델 나누기
- 데이터 나누기
Model parallel
- 모델을 나누는 것은 생각보다 예전부터 썼음
- alexnet
- 모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제

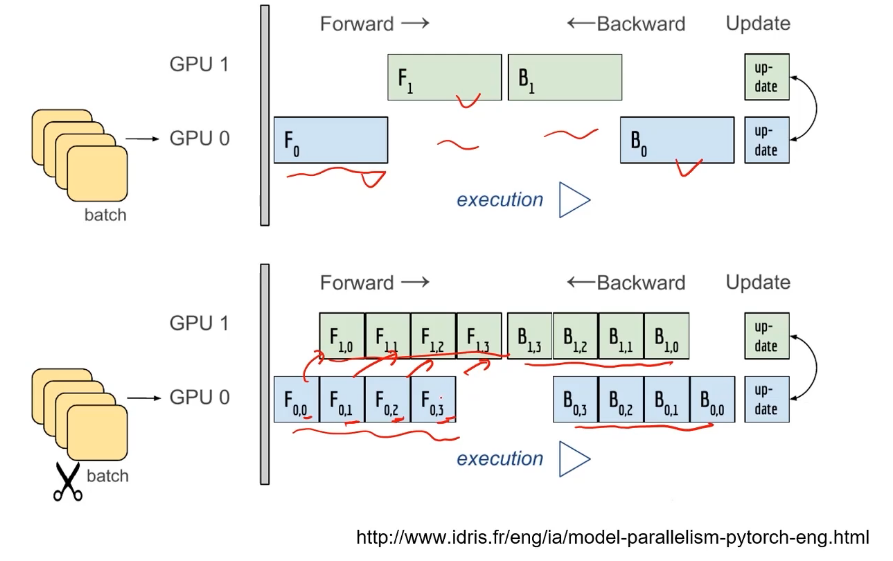
병렬적으로 처리되는 부분이 겹쳐야 좋은 병렬 처리가 가능
- 그림1의 위 예시는 병렬적으로 처리되는 부분이 겹치지 않기 때문에 병목 현상이 발생하게 됨
코드
class ModelParallelResNet50(ResNet): def __init__(sefl, *args, **kwargs): super(ModelParallelResNet, self).__init__( ~~ ) self.seq1 = nn.Sequential( ~~ ).to('cuda:0') # 첫번째 모델을 cuda 0(gpu 0)에 할당 self.seq2 = nn.Sequential( ~~ ).to('cuda:1') # 두번째 모델을 cuda 1(gpu 1)에 할당 self.fc.to('cuda:1') def forward(self, x): x = self.seq2(self.seq1).to('cuda:1') # 두 모델 seq1과 seq2를 cuda 1(gpu 1)에 연결하기 return self.fc(x.view(x.size(0), -1))
Data parallel
- 데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법
- minibatch 수식과 유사한데 한 번에 여러 GPU에서 수행
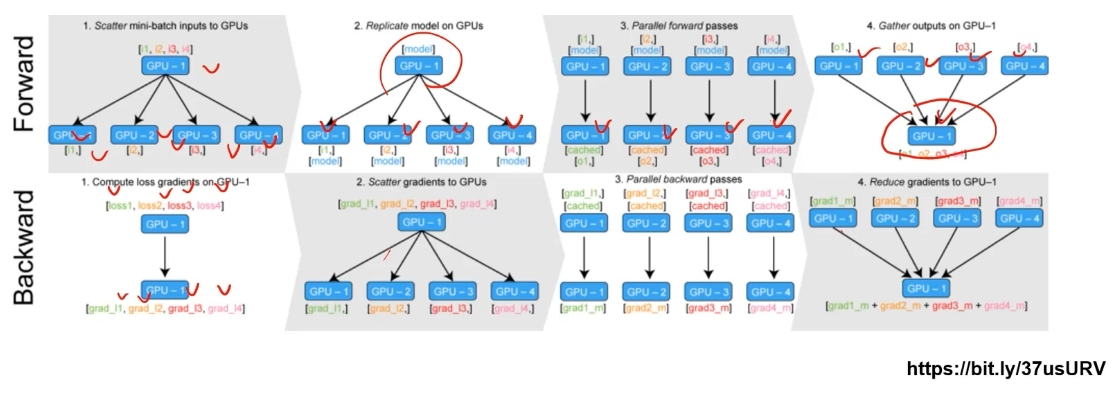
PyTorch에서는 아래 두 가지 방식을 제공
DataParallel
parallel_model = torch.nn.DataParallel(model) # 모델 캡슐화- 단순히 데이터를 분배한 후 평균을 취함
- GPU 사용 불균형 문제 발생
- Batch 사이즈 감소 (한 GPU가 병목)
- GIL (Global Interpreter Lock) 문제
- 단순히 데이터를 분배한 후 평균을 취함
DistributedDataParallel
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data) trainloader = torch.utils.data.DataLoader(train_data, batch_size=20, shuffle=False, pin_memory=True, num_workers=4, sampler=train_sampler)- pin_memory를 True로 설정하면 아래 그림과 같이 pageable memory와 pinned memory를 거쳐서 GPU에 데이터가 전달되는 것이 아니라 pinned memory에서 바로 GPU에 데이터가 전달된다.
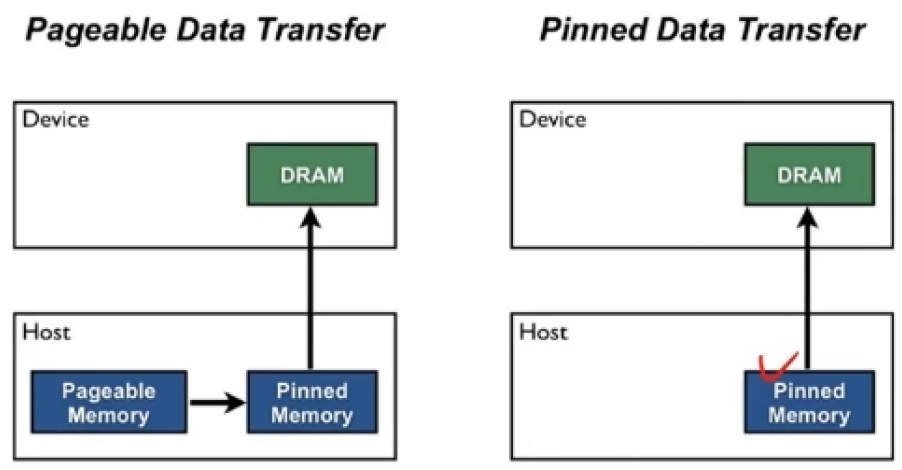
- pin_memory를 True로 설정하면 아래 그림과 같이 pageable memory와 pinned memory를 거쳐서 GPU에 데이터가 전달되는 것이 아니라 pinned memory에서 바로 GPU에 데이터가 전달된다.
코드
def main(): n_gpus = torch.cuda.device_count() # GPU 개수(ex: 4) torch.multiprocessing.spawn(main_worker, nprocs=n_gpus, args=(n_gpus, )) def main_worker(gpu, n_gpus): image_size = 224 batch_size = 512 num_worker = 8 epochs = 20 batch_size = int(batch_size / n_gpus) num_worker = int(num_worker / n_gpus) # 멀티프로세싱 통신 규약 정의 torch.distributed.init_process_group(backend='ncc1', init_method='tcp://127.0.0.1:2568', world_size=n_gpus, rank=gpu) torch.cuda.set_device(gpu) model = model.cuda(gpu) # Distributed DataParallel 정의 model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])각 CPU마다 process 생성하여 개별 GPU에 할당
- DataParallel을 통해 하나씩 개별적으로 연산한 후 연산들의 평균을 냄
참고 코드
# python의 멀티프로세싱 코드 from multiprocessing import Pool def f(x): return x*x if __name__ == '__main__': with Pool(5) as p: print(p.map(f, [1,2,3]))
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| PyTorch Troubleshooting (0) | 2023.05.24 |
|---|---|
| Hyperparameter Tuning (0) | 2023.05.23 |
| Monitoring tools for PyTorch (2) | 2023.05.20 |
| PyTorch 모델 불러오기 (0) | 2023.05.19 |
| Datasets과 Dataloaders (0) | 2023.05.18 |
'부스트캠프 AI Tech 4기' Related Articles
more




Comments