
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- AI 경진대회
- mrc
- AI Math
- 현대자동차
- passage retrieval
- Attention
- RNN
- GPT
- Optimization
- matplotlib
- word2vec
- seaborn
- Ai
- N21
- 기아
- KLUE
- nlp
- 2023 현대차·기아 CTO AI 경진대회
- dataset
- Data Viz
- 데이터 시각화
- 딥러닝
- Transformer
- N2N
- Bart
- 데이터 구축
- pyTorch
- Self-attention
- Bert
- ODQA
- Today
- Total
쉬엄쉬엄블로그
(KLUE) 자연어처리 연구 본문
이 색깔은 주석이라 무시하셔도 됩니다.
한국어 언어 모델 학습 및 다중 과제 튜닝
Transformer와 multi-modal 연구
BERT 이후의 LM
XLNet

Relative positional encoding 방식 적용 (Transformer-XL)
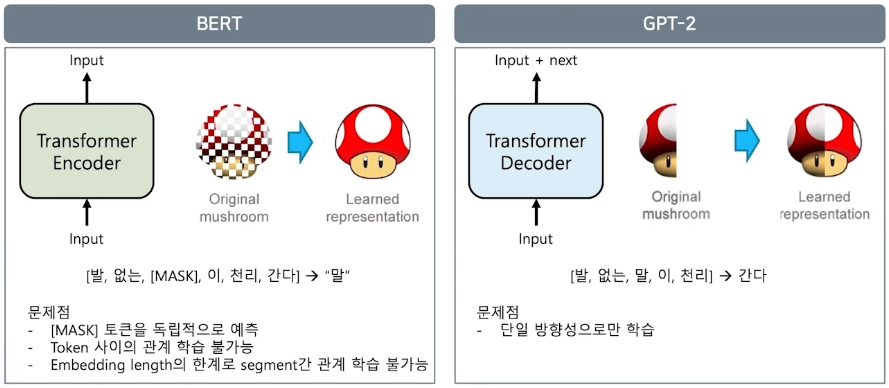
- sequence의 max length 길이 제한 문제를 해결하기 위한 방법
- Positional encoding → token간 관계성을 표현하기 위함
- BERT처럼 0, 1, 2, 3 … 으로 표현하는 것이 아니라, 현재 token의 위치 대비 0번째, 1번째, 2번째, … 상대적 거리 표현법을 사용
- Sequence 길이에 제한이 없어짐
Permutation langauge modeling
mask token을 없앰

- 순열 조합을 통해 순서를 모두 섞고 섞인 순서의 sequence가 학습의 대상이 됨
- 순서를 섞었기 때문에 한 방향으로만 학습하는 것을 방지할 수 있음
GLUE Benchmark

- 등장하자마자 기존 모델들의 성능을 한참 뛰어넘게 됨
RoBERTa
BERT 구조에서 학습 방법을 고민!
Model 학습 시간 증가 + Batch size 증가 + Train data 증가
Next sentence prediction 제거 → Fine-tuning과 관련 없음 + 너무 쉬운 문제라 오히려 성능 하락
Longer sentence 추가
Dynamic masking → 똑같은 텍스트 데이터에 대해 masking을 10번 다르게 적용하여 학습

- 문제를 어렵게 만들고 어려운 문제를 학습한 모델이 성능이 좋다
BART
Transformer Encoder-Decoder 통합 LM

- Token masking, Sentence permutation, Document rotation, Token detection, Text infilling 처럼 다양한 task들을 학습하도록 만듬
- 기존에 mask를 예측하는 task로만 학습했던 것이 BERT라면 BART는 온갖 어려운 task들을 한꺼번에 예측할 수 있게 만들었음
GLUE benchmark

T-5
Transformer Encoder-Decoder 통합 LM
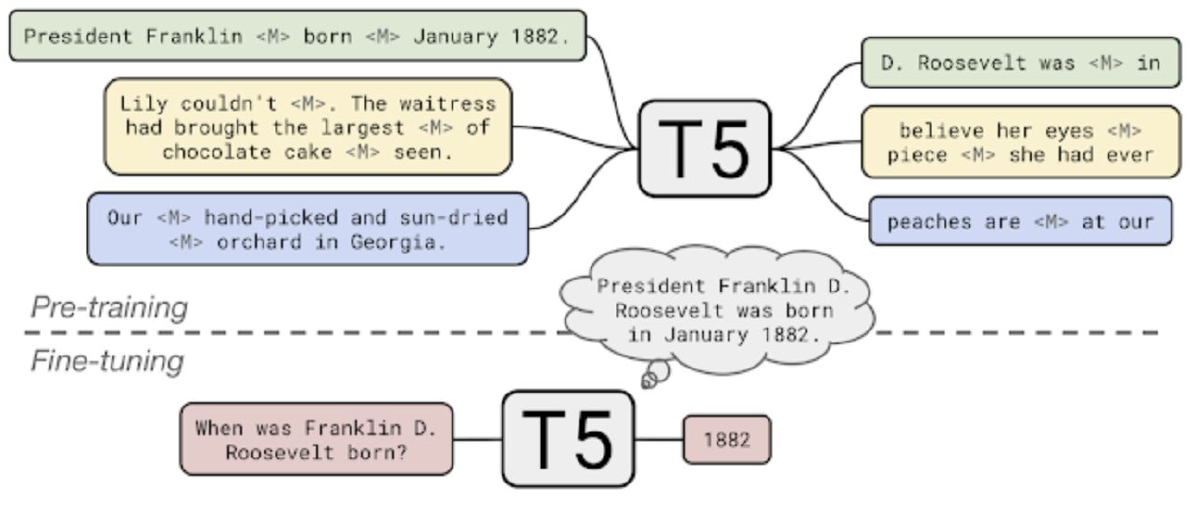
Pre training 과정에서 온갖 task들을 다양하게 학습할 수 있음
T-5 모델은 학습을 할 때 masking 기법을 사용
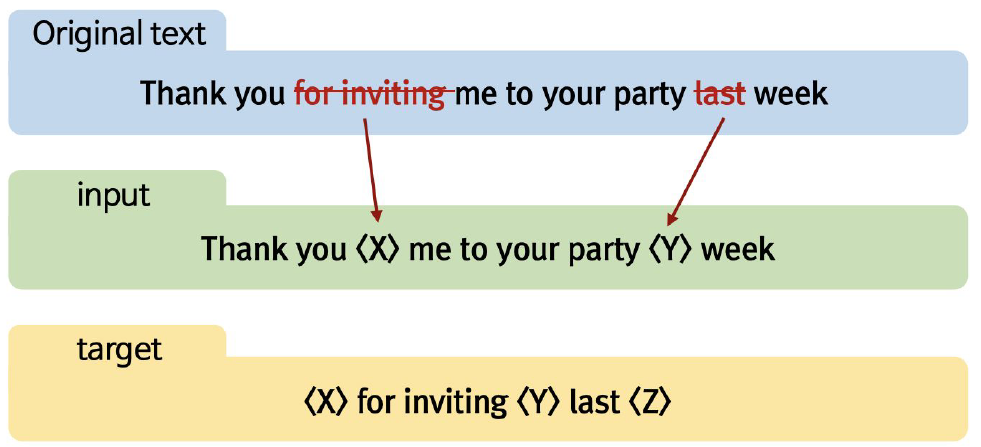
- 하지만 masking이 하나의 토큰만을 의미하는 것이 아니고 의미를 가진 여러 어절들을 동시에 mask하고 mask도 한번에 학습할 때 여러 개의 mult-mask를 다시 복원하는 과정으로 학습함
- 훨씬 어려운 문제로 학습하게 됨
GLUE benchmark

- T5가 NLU task에 대해서 가장 높은 성능을 보여주는 LM로 여겨지고 있음
Meena
대화 모델을 위한 LM

소셜 미디어의 데이터(341GB, 400억개의 단어)를 이용하여 26억개의 파라미터를 가진 신경망 모델을 이용한 end-to-end multi-turn 챗봇
챗봇의 평가를 위한 새로운 Metric인 SSA(Sensibleness and Specificity Average)를 제시
Sensibleness는 현재까지 진행 중인 대화에 가장 적절한 답변을 했는지 안했는지에 대한 점수
Specificity는 얼마나 구체적으로 답변했는지를 의미함
- 그냥 모른다고 대답하는 것도 적절한 답변이지만 구체적인 답변은 아닌 것

Controllable LM
Plug and Play Langauge Model (PPLM)
다음에 등장할 단어 → 확률 분포를 통해 선택
내가 원하는 단어들의 확률이 최대가 되도록 이전 상태의 vector를 수정
수정된 vector를 통해 다음 단어 예측

gradient를 업데이트하지 않고 기존에 학습한 모델을 바탕으로 내가 원하는 단어를 생성하도록 유도할 수 있음
확률 분포를 사용하는 것이기 때문에, 중첩도 가능 (기쁨 + 놀람 + 게임)
특정 카테고리에 대한 감정을 컨트롤해서 생성 가능
- 정치적, 종교적, 성적, 인종적 키워드에 대해서는 중립적인 단어를 선택해서 생성
- 범죄 사건에 대해서는 부정적인 단어를 선택해서 생성
확률 분포 조절을 통해 그라데이션 분노 가능

편향성이 제거된 데이터로 학습하면 편향성이 제거된 출력이 나온다는 것은 틀린 이야기
LM의 역할은 자연스럽고 풍부한 대화를 하기 위해 학습이 되어있다면 풍부한 대화 다음에 윤리성에 대한 모델 또는 모듈이 필요함
- 챗봇에서 유사도 비교를 통해 출력을 필터링한 것처럼 윤리성 평가 장치를 둬서 필터링할 수 있도록 대화 모델이 발전되고 있음
한국어 BoW 실험


과연 자연어 to 자연어로 충분할까?
- 우리가 언어를 배울 때, written language인 책만 보고 학습는가?
- 태어나서 첫 마디를 뗄 때까지, 우리는 spoken language를 통해 학습한다.
- 또한 인간은 시각, 청각, 후각, 촉각, 미각 등의 모든 감각을 통해 세상을 학습한다.
- 그렇다면 인공지능을 구현하기 위해 자연어 to 자연어로 충분할까?
- 부족하다! 그래서 최근에는 multi-modal language 모델 연구가 활발하게 진행 중!
Multi-modal Language Model
할머니세포(Grandmother cell)
Philip Roth (1969)의 소설 Portnoy’s Complaint

즉, ‘어머니’를 representation하는 concept neuron을 모두 제거하니, 해당 concept에 대한 기억이 사라짐
Jerry Lettvin는 소설에서 아이디어를 얻어 할머니 세포라는 개념을 제시(1969)
이 세포는 1개의 단일 세포가 어떤 개념(concept)에 대해 반응 (e.g. 할머니, 어머니)
- → 실제로 발견됨!
Electrophysiological recording - Microelectrode arrays (MEAs)


- 다양한 이미지들을 보여줬을 때 환자의 뇌세포가 활성이 어떻게 변화되는지 관찰
- 이때, 굉장히 재밌는 뉴런이 발견됨
- 이 뉴런을 Halle Berry neuron이라 함
- 수 많은 이미지를 보여줬는데 Halle Berry라는 여배우의 모습만 나타나면 이 뇌세포가 반응하기 시작
- 모습뿐만 아니라 글자와 배역, 그림에서도 반응함
- 즉, 우리의 뇌가 하나의 객체를 인지할 때 다양한 multi-modal 정보를 바탕으로 그 객체를 인지하게 된다는 것
LXMERT
Cross-modal reasoning language model
(Learning Cross-Modality Encoder Representations from Transformers)이미지와 자연어를 동시에 학습!

이미지와 자연어를 하나로 연결함
자연어의 임베딩된 정보와 이미지가 임베딩된 정보가 하나로 합쳐져서 Cross-Modality Output이라는 벡터가 만들어짐
- BERT에서 가정으로 뒀던 [CLS] 토큰 같은 개념
이미지 feature - 자연어 feature가 하나의 모델에 반영됨

ViLBERT
BERT for vision-and-language
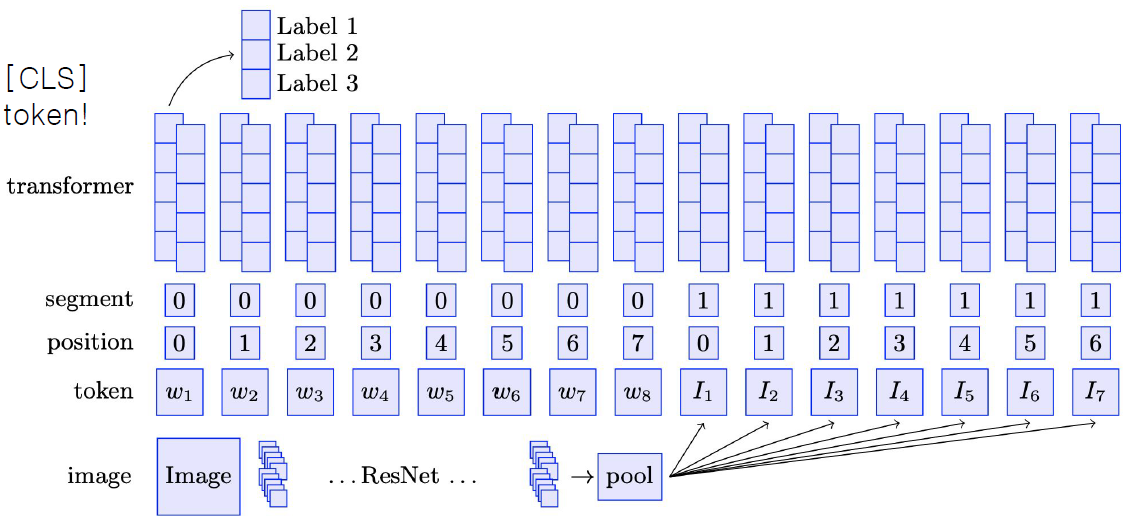

- BERT와 구조가 똑같음
- BERT는 일반적으로 문장1 [SEP] 문장2 를 입력으로 넣었음
- 이 모델은 앞에 이미지 토큰에 대한 임베딩 벡터를 넣고 SEP 토큰 다음에 자연어에 대한 벡터를 넣음
- 그래서 BERT는 이미지에 대한 토큰 벡터와 자연어에 대한 토큰 벡터를 합쳐서 CLS 토큰을 만들고 만들어진 CLS 토큰 위에 classification layer만 부착하면 자연어와 이미지가 합쳐져있는 정보(multi-modal 정보)를 통해서 분류하게 되는 task를 수행할 수 있게 됨
- 이미지만 보고 분류했을 때, 텍스트만 보고 분류했을 때, 이미지와 텍스트를 합쳐서 분류했을 때 성능을 비교해보면 이미지와 텍스트를 합쳐서 분류했을 때 성능이 가장 좋다고 함
- BERT와 구조가 똑같음
Dall-e
자연어로부터 이미지를 생성해내는 모델
아보카도 모양의 안락 의자 생성

아보카도 모양의 램프

VQ-VAE를 통해 이미지의 차원 축소 학습
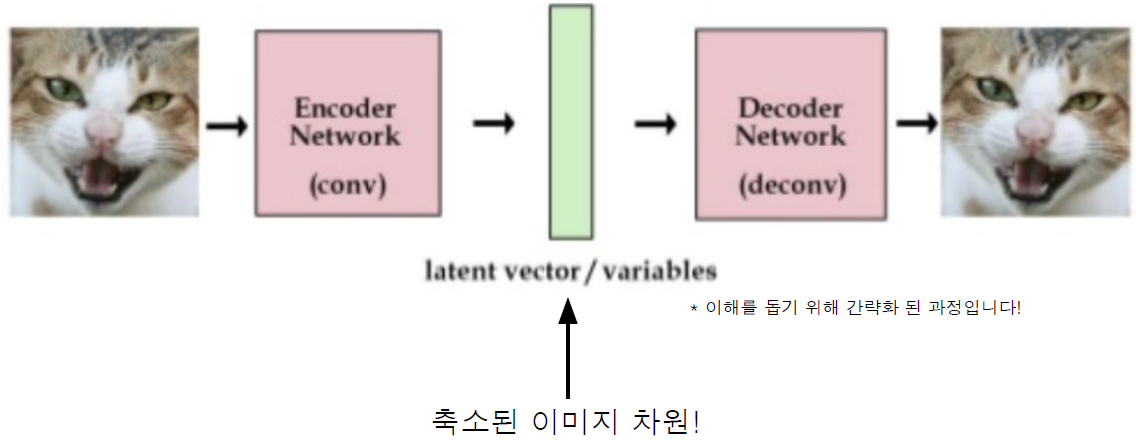
Autoregressive 형태로 다음 토큰 예측 학습

- 앞부분에는 텍스트에 대한 인코딩을 진행하여 텍스트 토큰이 들어감
- 이 텍스트를 위해 256 토큰을 할당함 (못채우면 패딩)
- 그 뒤에는 이미지 벡터를 생성해내도록 학습함
- GPT와 마찬가지로 텍스트 토큰이 입력으로 들어갔을 때 다음에 이미지 토큰을 생성해내는 방법으로 이미지를 만들어내도록 학습함
한국어 Dall-e 모델 실험
학습 데이터 : MSCOCO-2014 (13GB)
모델 사이즈 : Dall-e 대비 1/120

출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (데이터 제작) 자연어처리 데이터 기초 (0) | 2023.08.27 |
|---|---|
| (데이터 제작) 데이터 제작의 A to Z (0) | 2023.08.24 |
| (KLUE) GPT 언어 모델 (0) | 2023.08.22 |
| (KLUE) BERT 언어모델 기반의 두 문장 관계 분류 (0) | 2023.08.18 |
| (KLUE) BERT 언어모델 기반의 단일 문장 분류 (0) | 2023.08.17 |



