
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- passage retrieval
- 기아
- Bert
- Self-attention
- Transformer
- seaborn
- Data Viz
- 데이터 구축
- N21
- AI Math
- 데이터 시각화
- RNN
- mrc
- 2023 현대차·기아 CTO AI 경진대회
- KLUE
- Bart
- word2vec
- ODQA
- 현대자동차
- N2N
- Attention
- dataset
- AI 경진대회
- pyTorch
- matplotlib
- GPT
- Optimization
- nlp
- 딥러닝
- Ai
Archives
- Today
- Total
쉬엄쉬엄블로그
(NLP 기초대회) N2M - Encoder-Decoder Approach 실습 본문
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
N2M 실습
문제
날짜 정규화 데이터셋

- 입력 : 다양한 형태의 날짜 표기
- 출력 : YYYY-MM-DD 형식의 날짜 표기
- 개수 : 자체적으로 생성 가능
모델
입출력 디자인
Huggingface AutoTokenizer
Vocab 정보(facebook/bart-base 모델의 vocab)
- 크기 : 50265
- 문장 최대 길이 : 16
샘플 데이터
입력 데이터 : 18/01/1976
토큰화 결과 : [0, 1366, 73, 2663, 73, 44835, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1]

사용 모델
Huggingface AutoModelForSeq2SeqLM Model
선학습되지 않은 BART 아키텍처 활용
facebook/bart-base Config, Tokenizer 활용

Loss function
CrossEntropyLoss
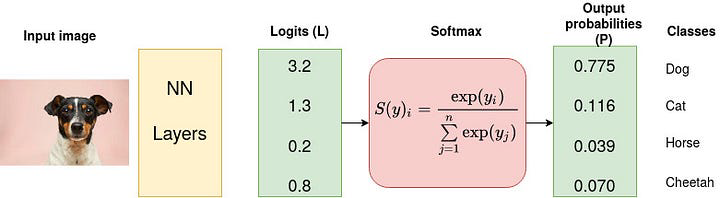
딥러닝의 출력 결과를 확률로 변환하여 Loss를 계산함
Softmax는 Logits을 확률로 변환하며, 이 때 확률의 합은 1이 됨
하이퍼파라미터 튜닝
하이퍼파라미터 튜닝
하이퍼파라미터의 조합은 무수히 많음
성능에 중요한 역할을 함
→ 사람 대신 기계가 찾아보자

하이퍼파라미터 튜닝 도구

WandB (Weights & Biases)

머신러닝 & 딥러닝 실험 결과 추적 툴
- 결과 시각화 Dashboard 제공
- Dataset, Model version 관리
- 하이퍼파라미터 튜닝
- 결과 정리 및 공유
WandB Sweep(하이퍼파라미터 튜닝) 예시

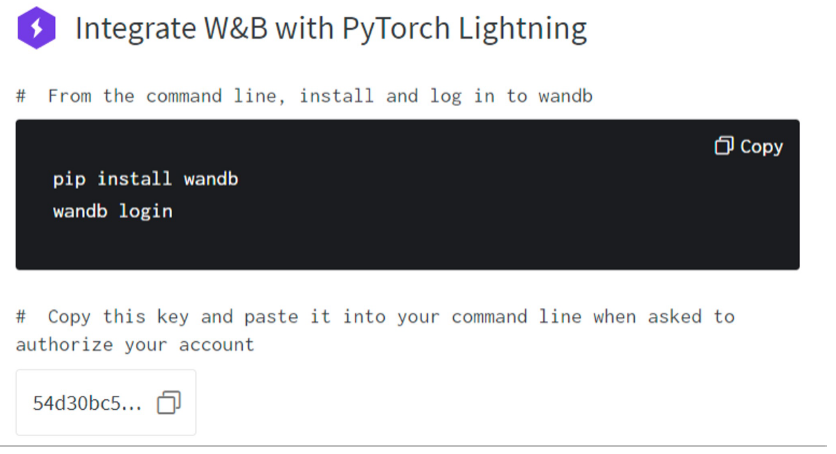
WandB 연결
회원가입

프로젝트 생성

설치 및 로그인
logger 설정

WandB sweep
Sweep config 작성

- 튜닝 방법 설정
- 평가지표 설정
- 하이퍼파라미터 및 범위 선택
데이터셋, 모델 작성 및 Sweep 실행

- 사용할 데이터셋과 모델 작성
- Sweep 실행
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)
'부스트캠프 AI Tech 4기' 카테고리의 다른 글
| (Data Viz) 주제별 시각화와 사용법 - Custom Matplotlib Theme (0) | 2023.07.31 |
|---|---|
| (NLP 기초대회) Prediction Service (0) | 2023.07.29 |
| (NLP 기초대회) N2M - Encoder-Decoder Approach (0) | 2023.07.27 |
| (NLP 기초대회) N2N - Token Classification 실습 (0) | 2023.07.26 |
| (NLP 기초대회) N2N - Token Classification (0) | 2023.07.25 |
'부스트캠프 AI Tech 4기' Related Articles
more




Comments