부스트캠프 AI Tech 4기
(NLP) Word Embedding
쉬엄쉬엄블로그
2023. 6. 19. 11:53
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
Word Embedding : Word2Vec, GloVe
What is Word Embedding?
- Word Embedding이란 자연어가 단어들을 정보의 기본 단위로 하는 단어들의 시퀀스라고 볼 때 각 단어들을 어떤 특정한 차원으로 이루어진 공간 상의 한 점 혹은 그 점의 좌표를 나타내는 벡터로 변환해주는 기법
- Express a word as a vector
- 단어를 벡터로 표현
- ‘cat’ and ‘kitty’ are similar words, so they have similar vector representations → short distance
- 고양이와 새끼고양이는 유사한 단어들, 그래서 두 단어는 유사한 벡터 표현을 가짐 → 가까운 거리로 표현
- ‘hamberger’ is not similar with ‘cat’ or ‘kitty’, so they have different vector representations → far distance
- 햄버거는 고양이, 새끼고양이와 유사하지 않음, 그래서 햄버거와 고양이, 새끼고양이는 다른 벡터 표현을 가짐 → 먼 거리로 표현
Word2Vec

- An algorithm for training vector representation of a word from context words (adjacent words)
- context 벡터(인접한 단어들)로부터 단어의 벡터 표현을 학습하는 알고리즘
- Assumption : words in similar context will have similar meanings
- 가정 : 유사한 문맥에 있는 단어들은 유사한 의미를 가질 것
- e.g.
- The cat purrs.
- This cat hunts mice.
Idea of Word2Vec
- “You shall know a word by the company it keeps” -J.R. Firth 1957
- Suppose we read the word “cat”
- “cat”이라는 단어를 읽는다고 가정해보자
- What is the probability P(w|cat) that we’ll read the word w nearby?
- “cat”이라는 단어 근처에서 아래 그림의 단어들을 읽을 확률이 얼마일까?

- “cat”이라는 단어 근처에서 아래 그림의 단어들을 읽을 확률이 얼마일까?
- Distributional Hypothesis : The meaning of “cat” is captured by the probability distribution P(w|cat)
- 분포 가설 : “cat”의 의미는 확률 분포 P(w|cat)에 의해서 포착됨
How Word2Vec Algorithm Works

- 각 문장별로 Sliding Window를 적용하여 중심 단어와 각 주변 단어를 단어 쌍으로 구성함
- hidden layer의 노드 수는 하이퍼파라미터
- 워드 임베딩을 수행하는 좌표 공간의 차원 수와 동일함
- 이 예제에서 임베딩 차원을 2로 세팅하면 입력, 출력 노드는 3차원, hidden layer는 2차원으로 구성
- I, study, math 로 단어가 3개이기 때문에 3차원?
Another Example

- A vector representation of ‘eat’ in $W_1$ has similar pattern with vectors of ‘apple’, ‘orange’, and ‘rice’ in $W_2$
- $W_1$에서 ‘eat’의 벡터 표현은 $W_2$에서 ‘apple’, ‘orange’, ‘rice’의 벡터와 유사한 패턴을 가짐
- When the input is ‘eat’, the model can predict ‘apple’, ‘orange’, or ‘rice’ for output, because the vectors have high inner product values
- 입력이 ‘eat’일 때 벡터의 inner product 값이 높기 때문에 모델은 ‘apple’, ‘orange’, ‘rice’를 예측할 수 있음
- ‘juice’의 input vector와 ‘drink’의 output vector가 매우 유사한 벡터 표현을 가짐
- ‘apple’와 ‘orange’, ‘milk’와 ‘water’의 input vector가 매우 유사한 벡터 표현을 가짐
Property of Word2Vec
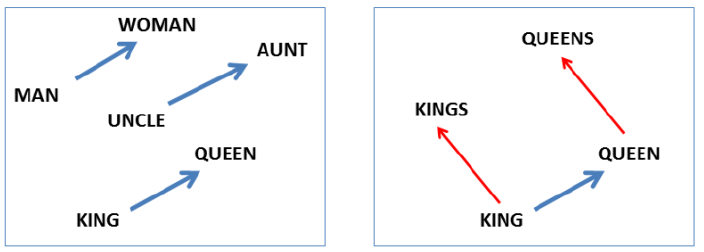
- The word vector, or the relationship between vector points in space, represents the relationship between the words.
- 단어 벡터 또는 공간 내의 벡터 점 사이의 관계는 단어 사이의 관계를 나타냄
- The same relationship is represented as the same vectors.
- 같은 관계는 같은 벡터로 표현됨
- e.g., vec[queen] - vec[king] = vec[woman] - vec[man]
Property of Word2Vec - Analogy Reasoning
- Korean Word2Vec : http://w.elnn.kr/search
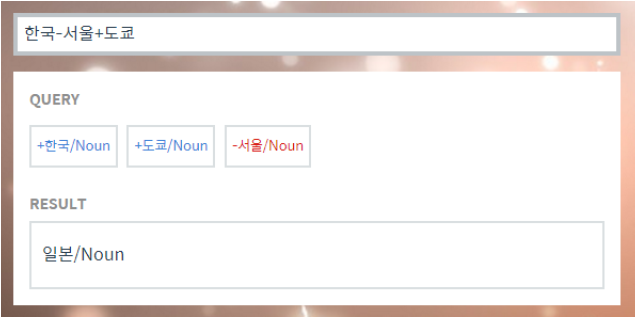
- More examples : http://wonjaekim.com/archives/50

Property of Word2Vec - Intrusion Detection
- Example : https://github.com/dhammack/Word2VecExample
- Word intrusion detction
- staple hammer saw drill
- math shopping reading science
- rain snow sleet sun
- eight six seven five three owe nine
- breakfast cereal dinner lunch
- england spain france italy greece germany portugal australia
- 특정 단어와 나머지 단어들 간의 유클리드 거리를 계산해서 평균을 취하면 그 값은 특정 단어가 나머지 단어들과 이루게 되는 평균 거리가 되고 평균 거리를 각 단어에 대해서 모두 구한 후 평균 거리가 가장 큰 단어를 구하게 되면 주어진 단어들 중 가장 의미가 상이한(다른) 단어라고 볼 수 있음
Application of Word2Vec
- Word2Vec improves performances in most areas of NLP
- Word2Vec은 NLP의 대부분의 영역에서 성능을 끌어올림
- Word similarity
- Machine translation

- Part-of-speech (PoS) tagging
- Named entity recognition (NER)
- Sentiment analysis

- Clustering
- Semantic lexicon building
- Image Captioning

GloVe : Another Word Embedding Model
- GloVe : Global Vectors for Word Representation
- Rather than going through each pair of an input and an output words, it first computes the co-occurrence matrix, to avoid training on identical word pairs repetitively.
- 입력 및 출력 단어의 각 쌍을 살펴보는 대신, 동일한 단어 쌍에 대한 반복 훈련을 피하기 위해 먼저 co-occurrence matrix(동시 발생 행렬)를 계산함
- Afterwords, it performs matrix decomposition on this co-occurrence matrix.
- 그 다음에, co-occurence matrix에 대해 행렬 분해를 수행한다.

- $P_{ij}$ : 두 단어가 한 윈도우 내에서 동시에 등장한 횟수
- $J(\theta)=\frac{1}{2}\sum^W_{i,j=1}f(P_{ij})(u_i^Tv_j-logP_{ij})^2$
- 그 다음에, co-occurence matrix에 대해 행렬 분해를 수행한다.
- Fast training
- Works well even with a small corpus
- 각 입출력 단어 쌍들에 대해서 두 단어가 한 윈도우 내에서 몇 번 동시에 등장했는지 사전에 미리 계산하고 그 값에 로그 값을 취하고 입출력 단어의 임베딩 벡터간의 내적 값이 미리 계산한 값에 가까워질 수 있도록 loss function을 만듬
- Word2Vec에 비해 빠르고 적은 데이터에 대해서도 잘 동작함
- 다양한 task에 적용했을 때 Word2Vec과 GloVe 둘 다 비슷한 성능이 나옴
- Rather than going through each pair of an input and an output words, it first computes the co-occurrence matrix, to avoid training on identical word pairs repetitively.
Property of GloVe - Linear Substructure
- man - woman
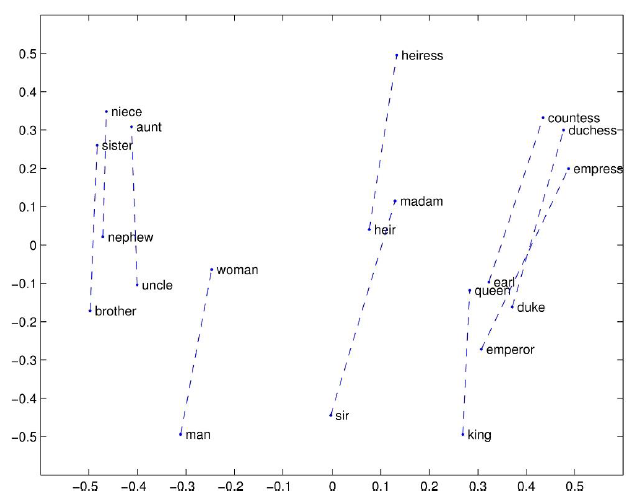
Distributed Representations of Words and Phrases and their Compositionality, NeurIPS’13 - company - ceo

Distributed Representations of Words and Phrases and their Compositionality, NeurIPS’13 - city - zip code

Distributed Representations of Words and Phrases and their Compositionality, NeurIPS’13 - comparative - superlative

Distributed Representations of Words and Phrases and their Compositionality, NeurIPS’13
GloVe : Global Vectors for Word Representation
References
- Word2Vec
- Distributed Representations of Words and Phrases and their Compositionality, NeurIPS’13
- GloVe
- GloVe : Global Vectors for Word Representation, EMNLP’14
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)