부스트캠프 AI Tech 4기
Hyperparameter Tuning
쉬엄쉬엄블로그
2023. 5. 23. 13:04
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
성능 향상 방법들
- 모델 구조 변경
- 데이터 증강
- 하이퍼파라미터 튜닝
- 보통 하이퍼파라미터 튜닝이 마지막으로 시도하는 방법
- 데이터 증강이 성능 향상에 가장 도움된다고 함
Hyperparameter Tuning
- 모델 스스로 학습하지 않는 값은 사람이 지정
- leanring rate
- 모델의 크기
- optimizer
- 등등
- 하이퍼 파라미터에 의해서 성능이 크게 좌우될 때도 있기 때문에 마지막 0.01을 쥐어짜야 할 때 도전해볼만 함
- 가장 기본적인 방법들

- grid
- random
- 최근에는 베이지안 기반 기법들이 주도
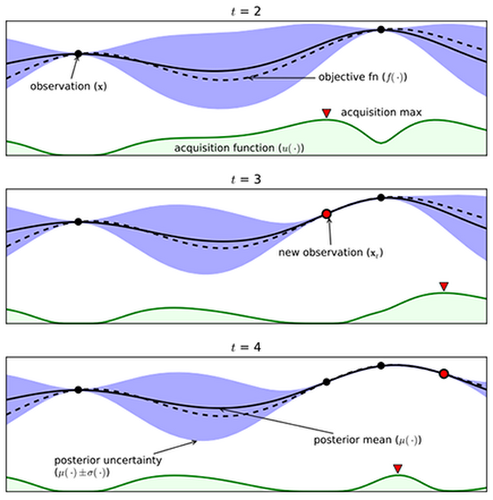
Gaussian process approximation of objective function from Eric Brochu, Cora and Freitas 2010 - BOHB (2018)
Ray
- mutli-node mutli processing 지원 모듈
- ML/DL의 병렬 처리를 위해 개발된 모듈
- 기본적으로 현재의 분산병렬 ML/DL 모듈의 표준
- Hyperparameter Search를 위한 다양한 모듈 제공
data_dir = os.path.abspath("./data")
load_data(data_dir)
# config에 search space 지정
config = {
"l1": tune.sample_from(lambda_: 2 ** np.random.randint(2, 9)),
"l2": tune.sample_from(lambda_: 2 ** np.random.randint(2, 9)),
"lr": tune.loguniform(1e04, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16])
}
# 학습 스케줄링 알고리즘 지정
scheduler = ASHAScheduler(metric="loss", mode="min", max_t=max_num_epochs, grace_period=1, reduction_factor=2)
# 결과 출력 양식 지정
reporter = CLIReporter(metric_columns=["loss", "accuracy", "training_iteration"])
# 병렬 처리 양식으로 학습 시행
result = tune.run(
partial(train_cifar, data_dir=data_dir),
resources_per_trial={"cpu":2, "gpu":gpus_per_trial},
config=config, num_samples=num_samples,
scheduler=scheduler,
progress_reporter=reporter)- 쓸만한 metric만 남기면서 학습을 진행함
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)