부스트캠프 AI Tech 4기
Monitoring tools for PyTorch
쉬엄쉬엄블로그
2023. 5. 20. 12:29
728x90
학습 기록을 위한 유용한 도구들
- Tensorboard
- weight & biases
Tensorboard
TensorFlow의 프로젝트로 만들어진 시각화 도구
학습 그래프, metric, 학습 결과의 시각화 지원
PyTorch도 연결 가능 → DL 시각화 핵심 도구
scalar : metric 등 상수 값의 연속(epoch)을 표시
grpah : 모델의 computational graph 표시
histogram : weight 등 값의 분포를 표현
image : 예측 값과 실제 값을 비교 표시
mesh : 3d 형태의 데이터를 표현하는 도구
Tensorboard 기록을 위한 directory 생성
import os logs_base_dir = "logs" os.makedirs(logs_base_dir, exist_ok=True)기록 생성 객체 SummaryWriter 생성
from torch.utils.tensorboard import SummaryWriter # default `log_dir` is "runs" - we'll be more specific here writer = SummaryWriter('app/fashion_mnist_experiment_1')jupyter 상에서 tensorboard 수행
%load_ext tensorboard파일 위치 지정 (app)
%tensorboard --logdir "app"- 같은 명령어를 콘솔에서도 사용 가능
Tensorboard에 데이터(이미지) 출력하기
# get some random training images images, labels = next(iter(trainloader)) # create grid of images img_grid = torchvision.utils.make_grid(images) print(img_grid.shape) # write to tensorboard writer.add_image('four_fashion_mnist_images', img_grid)
Tensorboard에 graph 추가하기
writer.add_graph(net, images) writer.close()
Tensorboard에 학습한 모델의 loss graph 추가하기
running_loss = 0.0 for epoch in range(2): # loop over the dataset multiple times print(epoch) for i, data in enumerate(trainloader, 0): # get the inputs; data is a list of [inputs, labels] inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() if i % 1000 == 999: # every 1000 mini-batches... # ...log the running loss writer.add_scalar('training loss', running_loss / 1000, epoch * len(trainloader) + i) running_loss = 0.0
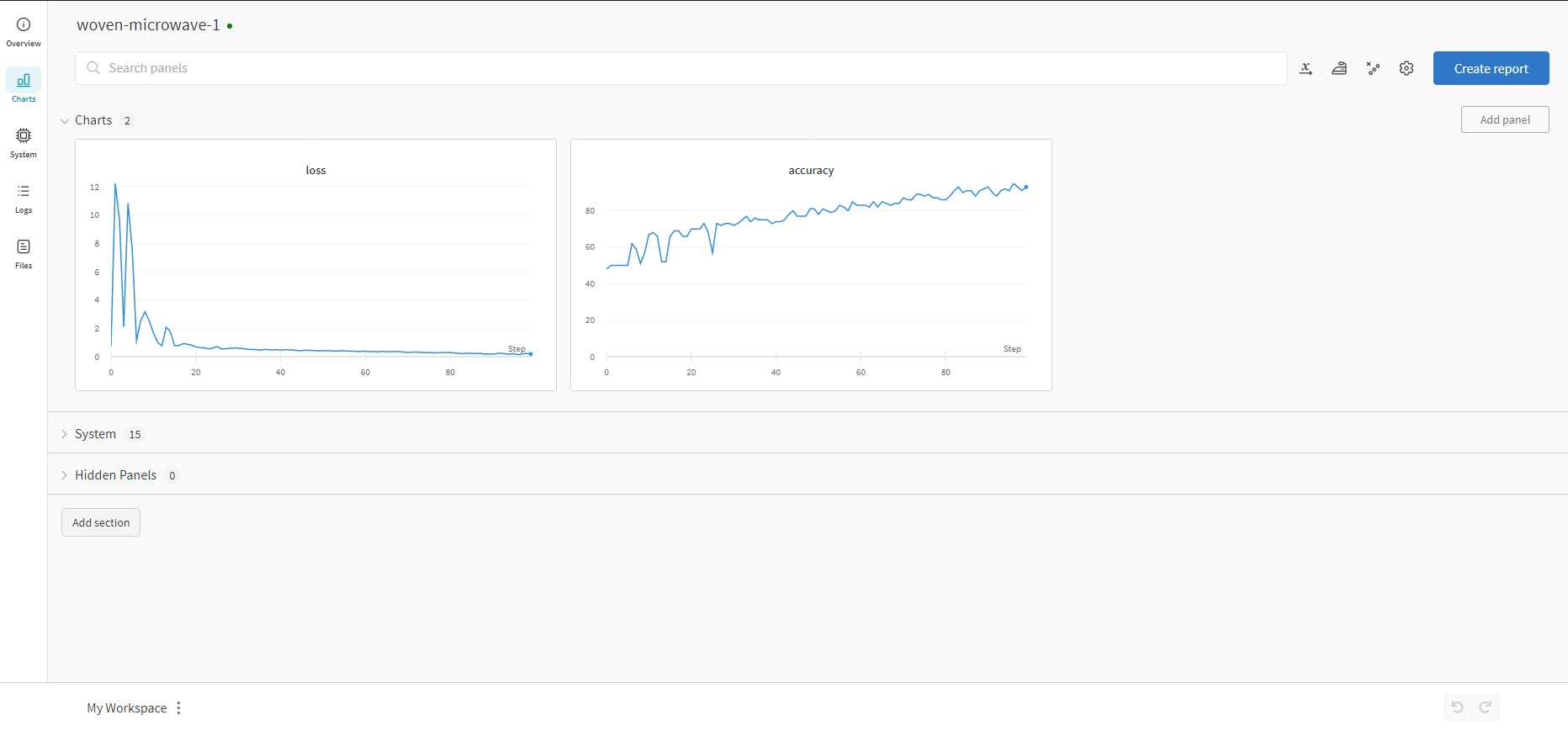
weight & biases
머신러닝 실험을 원활히 지원하기 위한 상용도구
협업, code versioning, 실험 결과 기록 등 제공
MLOps의 대표적인 툴로 저변 확대 중
install & import
!pip install wandb -q import wandbwandb에 학습 기록
EPOCHS = 100 BATCH_SIZE = 32 LEARNING_RATE = 0.001 config={"epochs": EPOCHS, "batch_size": BATCH_SIZE, "learning_rate" : LEARNING_RATE} wandb.init(project="my-test-project", config=config) # wandb.config.batch_size = BATCH_SIZE # wandb.config.learning_rate = LEARNING_RATE for e in range(1, EPOCHS+1): epoch_loss = 0 epoch_acc = 0 for X_batch, y_batch in train_dataset: X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor) optimizer.zero_grad() y_pred = model(X_batch) loss = criterion(y_pred, y_batch.unsqueeze(1)) acc = binary_acc(y_pred, y_batch.unsqueeze(1)) loss.backward() optimizer.step() epoch_loss += loss.item() epoch_acc += acc.item() train_loss = epoch_loss/len(train_dataset) train_acc = epoch_acc/len(train_dataset) print(f'Epoch {e+0:03}: | Loss: {train_loss:.5f} | Acc: {train_acc:.3f}') wandb.log({'accuracy': train_acc, 'loss': train_loss})