부스트캠프 AI Tech 4기
Datasets과 Dataloaders
쉬엄쉬엄블로그
2023. 5. 18. 18:08
728x90
모델에 데이터를 먹이는 방법
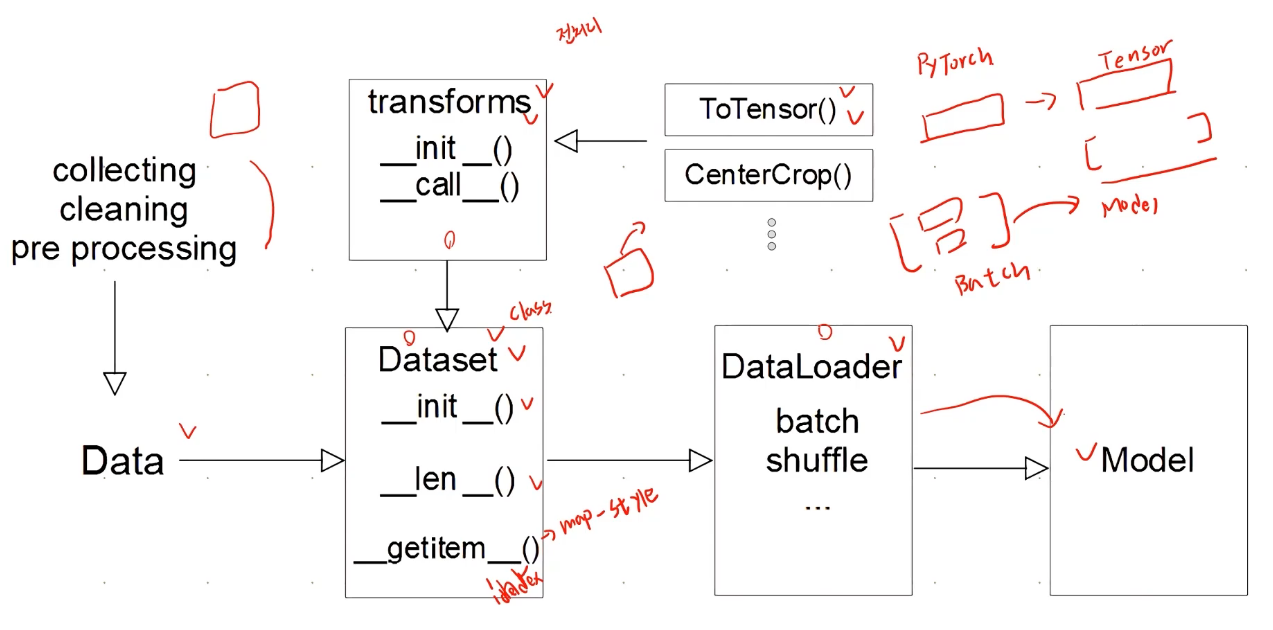
- _getitem_
- 하나의 데이터를 불러올 때 어떻게 반환을 해주는지에 대해서 정의해줌
- transforms
- 데이터 전처리를 정의
Dataset 클래스
- 데이터 입력 형태를 정의하는 클래스
- 데이터를 입력하는 방식의 표준화
- Image, Text, Audio 등에 따라 다른 입력 정의
Dataset 클래스의 스타일 2가지
Map-style
- index가 존재하여 data[index]로 데이터를 참조할 수 있음
- _getitem__과 _len 선언 필요
import torch
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
# 초기 데이터 생성 방법 지정
def __init__(self, text, labels):
self.labels = labels
self.data = text
# 데이터의 전체 길이 반환
def __len__(self):
return len(self.labels)
# index 값을 주었을 때 반환되는 데이터 형태 (X, y)
def __getitem__(self, idx):
label = self.labels[idx]
text = self.data[idx]
sample = {"Text": text, "Class": label}
return sample
# 사용 예시
text = ['Happy', 'Amazing', 'Sad', 'Unhappy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels)
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))
'''
{'Text': ['Glum', 'Amazing'], 'Class': ['Negative', 'Positive']}
'''
MyDataLoader = DataLoader(MyDataset, batch_size=3, shuffle=True)
for dataset in MyDataLoader:
print(dataset)
'''
{'Text': ['Unhappy', 'Amazing', 'Glum'], 'Class': ['Negative', 'Positive', 'Negative']}
{'Text': ['Happy', 'Sad'], 'Class': ['Positive', 'Negative']}
'''Iterable-style
- random으로 읽기에 어렵거나, data에 따라 batch size가 달라지는 데이터(dynamic batch size)에 적합
- 비교하자면 stream data, real-time log 등에 적합
- _iter_ 선언 필요
import torch
from torch.utils.data import IterableDataset, DataLoader
class CustomDataset(IterableDataset):
def __init__(self,data):
self.data = data
def __iter__(self):
return iter(self.data)
# 사용 예시
data = [1, 2, 3, 4, 5]
MyDataset = CustomDataset(data)
dataset = DataLoader(MyDataset, batch_size=2)
# 데이터셋 순회
for item in dataset:
# 아이템 처리
# ...
print(item)
'''
tensor([1, 2])
tensor([3, 4])
tensor([5])
'''Dataset 클래스 생성시 유의점
- 데이터 형태에 따라 각 함수를 다르게 정의함
- 모든 것을 데이터 생성 시점에 처리할 필요는 없음
- image의 Tensor 변화는 학습에 필요한 시점에 변환
- 최근에는 HuggingFace 등 표준화된 라이브러리 사용
DataLoader 클래스
- Data의 Batch를 생성해주는 클래스
- 학습직전(GPU feed전) 데이터의 변환을 책임
- Tensor로 변환 + Batch 처리가 메인 업무
- 병렬적인 데이터 전처리 코드의 고민 필요
DataLoader(dataset, # Dataset 인스턴스
batch_size=1, # 배치 사이즈 설정
shuffle=False, # 데이터를 섞을지 설정
sampler=None, # sampler는 index를 컨트롤
batch_sampler=None, # 위와 비슷하므로 생략
num_workers=0, # 데이터를 불러올 때 사용하는 서브 프로세스 개수
collate_fn=None, # map-style 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능
pin_memory=False, # Tensor를 CUDA 고정 메모리에 할당
drop_last=False, # 마지막 batch 사용 여부
timeout=0, # data load 제한시간
worker_init_fn=None # 어떤 worker를 불러올 것인가를 리스트로 전달
)collate_fn 예시
def collate_fn(batch): # 배치에서 샘플의 리스트를 가져온다. texts = [item["Text"] for item in batch] # 배치에서 레이블의 리스트를 가져온다. labels = [item["Class"] for item in batch] # 필요한 경우 데이터 전처리 또는 변환 작업을 수행한다. # 예를 들어, 샘플 텍스트에 !를 추가할 수 있다. texts = [f'{text}!' for text in texts] return texts, labelscollate_fn 적용 예시
MyDataLoader = DataLoader(MyDataset, batch_size=3, collate_fn=collate_fn) for dataset in MyDataLoader: texts, labels = dataset print(texts, labels) ''' ['Happy!', 'Amazing!', 'Sad!'] ['Positive', 'Positive', 'Negative'] ['Unhappy!', 'Glum!'] ['Negative', 'Negative'] ''' MyDataLoader = DataLoader(MyDataset, batch_size=3, shuffle=True, collate_fn=collate_fn) for dataset in MyDataLoader: texts, labels = dataset print(texts, labels) ''' ['Sad!', 'Unhappy!', 'Happy!'] ['Negative', 'Negative', 'Positive'] ['Amazing!', 'Glum!'] ['Positive', 'Negative'] '''