(MRC) Passage Retrieval-Scaling Up
이 색깔은 주석이라 무시하셔도 됩니다.
Passage Retrieval - Scailing Up
Passage Retrieval and Similarity Search
복습 Retrieval with dense embedding

인퍼런스 : Passage와 query를 각각 임베딩한 후 query로부터 거리가 가까운 순서대로 passage에 순위를 매김


MIPS(Maximum Inner Product Search)
주어진 질문(query) 벡터 q에 대해 Passage 벡터 v들 중 가장 질문과 관련된 벡터를 찾아야함
여기서 관련성은 내적(inner product)이 가장 큰 것

4, 5강에서 사용한 검색 방법 : brute-force(exhaustive) search
- 저장해둔 모든 Sparse/Dense 임베딩에 대해 일일히 내적값을 계산하여 가장 값이 큰 passage를 추출
MIPS in Passage Retrieval

MIPS & Challenges
- 실제로 검색해야할 데이터는 훨씬 방대함
- 5백만 개(위키피디아)
- 수십억, 조 단위까지 커질 수 있음
- ⇒ 따라서 더이상 모든 문서 임베딩을 일일히 보면서 검색할 수 없음
- 실제로 검색해야할 데이터는 훨씬 방대함
Tradeoffs of similarity search
Search Speed
- 쿼리당 유사한 벡터를 k개 찾는데 얼마나 걸리는지?
- ⇒ 가지고 있는 벡터량이 클 수록 더 오래 걸림
Memory Usage
- 벡터를 사용할 때, 어디에서 가져올 것 인지?
- ⇒ RAM에 모두 올려둘 수 있으면 빠르지만, 많은 RAM 용량을 요구함
- ⇒ 디스크에서 계속 불러와야한다면 속도가 느려짐
Accuracy
- brute-force 검색 결과와 얼마나 비슷한지?
- ⇒ 속도를 증가시키려면 정확도를 희생해야하는 경우가 많음

Tradeoff of search speed and accuracy
속도(search time)와 재현율(recall)의 관계
더 정확한 검색을 하려면 더 오랜 시간이 소모됨

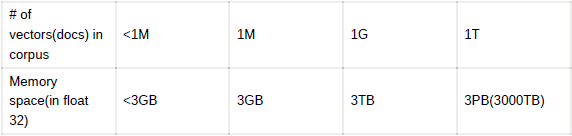
Increasing search space by bigger corpus
- 코퍼스(corpus)의 크기가 커질 수록
- 탐색 공간이 커지고 검색이 어려워짐
- 저장해 둘 Memory space 또한 많이 요구됨
- Sparse Embedding의 경우 이러한 문제가 훨씬 심함
- 예) 1M docs, 500K distint terms = 2TB
- 각 문서를 768차원의 벡터로 표현한 경우
- 코퍼스(corpus)의 크기가 커질 수록
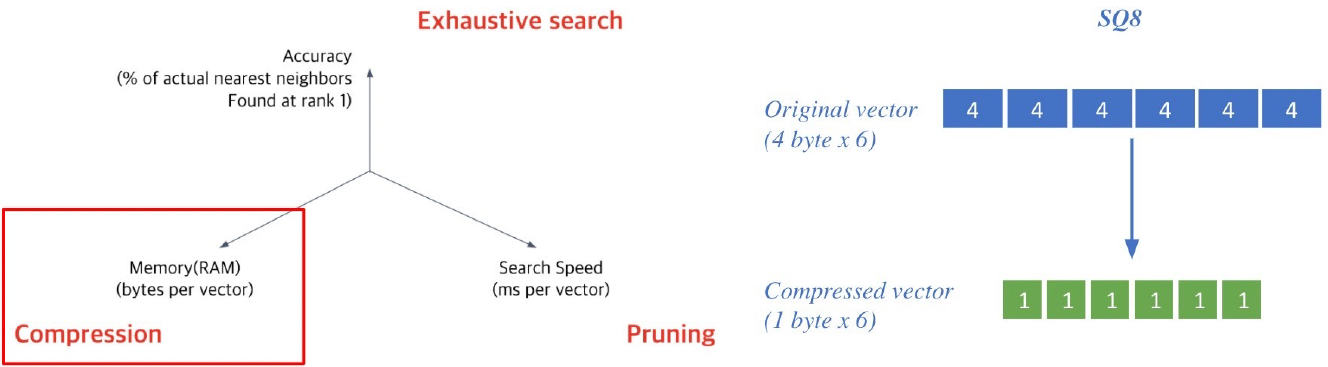
Approximating Similarity Search
Compression - Scalar Quantization (SQ)
Compression : vector를 압축하여, 하나의 vector가 적은 용량을 차지 ⇒ 압축량↑ ⇒ 메모리↓, 정보 손실↑
ex) Scalar quantization : 4-byte floating point ⇒ 1-byte (8bit) usigned integer로 압축
Pruning - Inverted File (IVF)
- Pruning : Search space를 줄여 search 속도 개선 (dataset의 subset만 방문)
- ⇒ Clustering + Inverted file을 활용한 search
Clustering : 전체 vector space를 k개의 cluster로 나눔 (ex. k-means clustering)

Inverted file (IVF)
Vector의 index = inverted list structure
⇒ (각 cluster의 centroid id)와 (해당 cluster의 vector들)이 연결되어있는 형태

Searching with clustering and IVF
주어진 query vector에 대해 근접한 centroid 벡터를 찾음
찾은 cluster의 inverted list 내 vector들에 대해 서치 수행

Introduction to FAISS
What is FAISS
tutorial : https://github.com/facebookresearch/faiss/tree/main/tutorial/python

FAISS : Library for efficient similarity search
indexing쪽 도움을 주고 encoding쪽 도움을 주고 있는 부분은 아님

Passage Retrieval with FAISS
Train index and map vectors

- train과 add 단계가 있음
Search based on FAISS index
nprobe : 몇 개의 가장 가까운 cluster를 방문하여 search 할 것인지

Scaling up with FAISS
FAISS Basics
brute-force로 모든 벡터와 쿼리를 비교하는 가장 단순한 인덱스 만들기
준비하기

인덱스 만들기

검색하기

IVF with FAISS
IVF 인덱스 만들기
클러스터링을 통해서 가까운 클러스터 내 벡터들만 비교함
빠른 검색 가능
클러스터 내에서는 여전히 전체 벡터와 거리 비교(Flat)
IVF 인덱스

IVF-PQ with FAISS
벡터 압축 기법(PQ) 활용하기
전체 벡터를 저장하지 않고 압축된 벡터만을 저장
메모리 사용량을 줄일 수 있음
IVF-PQ 인덱스

Using GPU with FAISS
GPU의 빠른 연산 속도를 활용할 수 있음
- 거리 계산을 위한 행렬곱 등에서 유리
다만, GPU 메모리 제한이나 메모리 random access 시간이 느린 것 등이 단점
단일 GPU 인덱스

Using Multiple GPUs with FAISS
여러 GPU를 활용하여 연산 속도를 한층 더 높일 수 있음
다중 GPU 인덱스

출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)