(데이터 제작) 데이터 구축 작업 설계
이 색깔은 주석이라 무시하셔도 됩니다.
데이터 구축 작업 설계
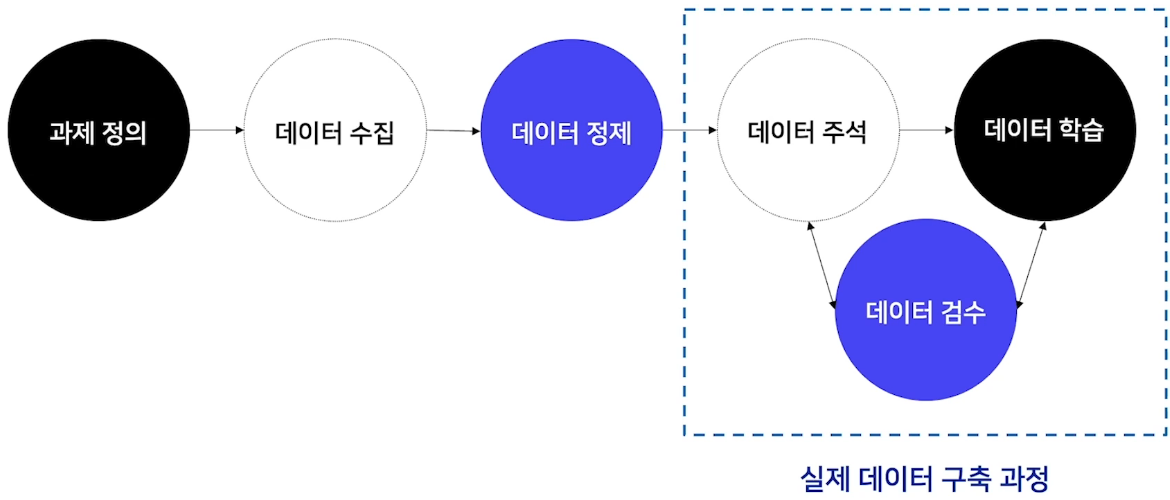
데이터 구축 프로세스
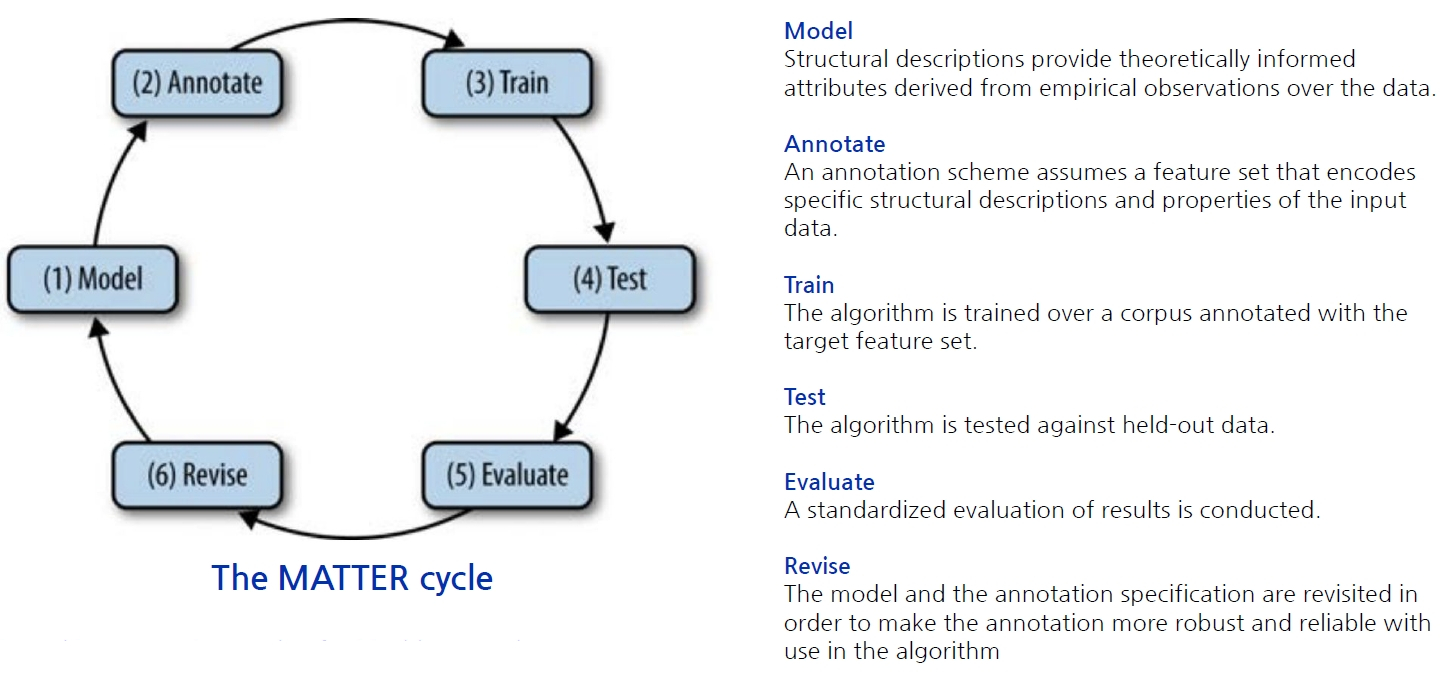

- Revising the spec while working on the guidelines and doing the an annotation occurs frequently enough that we refer to it as the MAMA cycle: Model-Annotate-Model-Annotate(the Annotate step includes writing the guidelines)
- 지침을 작성하고 주석하는 동안 spec(설계?)을 수정하는 경우가 MAMA 사이클(Model-Annotate-Model-Annotate)이라고 불릴 정도로 자주 발생한다(주석 단계에는 지침 작성이 포함된다).
예시

데이터 구축 프로세스 정의 예시

http://knconsulting.co.kr/knowledge/? q=YToyOntzOjQ6InBhZ2UiO2k6MTtzOjEyOiJrZXl3b3JkX3R5cGUiO3M6MzoiYWxsIjt9&bmode=view&idx=6009133&t=board&category=bgG5885


- 표와 글로 작성하는 것은 하지 않더라도 전체 흐름도를 한 번 그려보는 것이 이해하는 데 많은 도움이 될 것
데이터 주석
데이터 주석 유형 1 분류

- 문장 또는 텍스트에 대해 분류 레이블을 주석하는 유형 : 감성 분석, 주제 분류, 자연어 추론 등
- 구축 난이도는 일반적으로 낮은 편
데이터 주석 유형 2 특정 범위(span) 주석
텍스트의 일부를 선택하여 특정한 레이블을 주석하는 유형
개체명

형태 분석

등등
데이터 주석 유형 3 대상 간 관계 주석
대상 간 관계를 주석하는 유형
관계 추출
개체명 연결

구문 분석
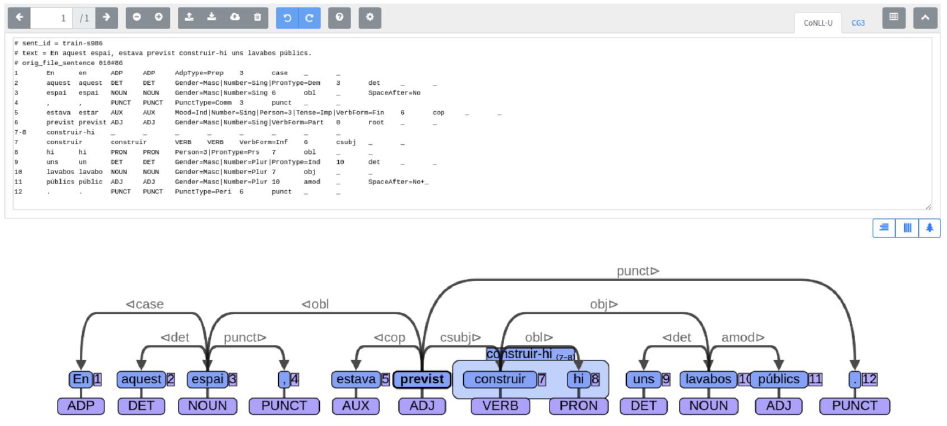
https://aclanthology.org/W17-7604.pdf 등등
두 단계에 걸쳐 구축해야 하므로 구축 난이도는 높은 편
UAS, LAS라는 평가 지표가 있음
데이터 주석 유형 4 텍스트 생성
주어진 텍스트에 대한 텍스트 또는 발화를 생성하는 유형
대화문
번역

요약
등등
데이터 주석 유형 5 그 외 - 복합 유형

- 앞선 유형의 데이터 구축 방식을 복합적으로 사용하여 다양한 정보를 주석하는 유형
- 질의 응답, 슬롯필링 대화 등
데이터 검수
가이드라인 정합성
- 각 주석 절차 및 주석 내용이 가이드라인에 부합하는지 확인
데이터 형식
- 메타 정보, 레이블, 텍스트 내용 등의 형식이 맞는 확인
통계 정보
- 메타 정보 및 레이블의 분포, 문장 길이, 단위 별 규모 확인
모델 성능 확인
- 모델 학습을 통해 결과값 확인
- 모델 성능이 잘 나오는 데이터가 좋은 데이터인 것은 아님
- 좋은 데이터는 위에서 얘기한 기준들에 부합하는 데이터이고 데이터 자체는 데이터 자체로 완결성이 있어야 함
오류 원인 분석
- 구축방법 측면의 오류 원인 : 모델·데이터의 대상 선정, 수집, 정제, 라벨링 등의 통제 미흡으로 인하여 구축 절차, 구조, 학습모델 측면의 다양한 오류 데이터 생성
- 가이드라인 측면의 오류 원인 : 구축 가이드라인의 불완전성, 미준수로 인하여 작업자간 서로 상이하게 작업을 수행하거나 데이터간 일관성 위배
- 데이터셋 측면의 오류 원인 : 데이터셋 설계의 부족, 구문정확성 위배, 데이터 구축 중복 등
- 학습모델 측면의 오류 원인 : 학습모델에 적합한 데이터 구축이 수행되지 않았거나, 잘못된 학습모델 선정으로 데이터 구축 방향이 잘못된 경우
데이터 검수 유형

- 데이터가 적다면 전수 검사를 하지만 데이터가 너무 많다면 표본 추출을 통해 검수함
데이터 평가

- 작업자 간 일치도는 볼 수 있는 태스크가 있고 볼 수 없는 태스크가 있음
- 작업자 간 일치도는 여건상 보지 못하는 경우가 많음
- Cohen’s k와 Fleiss’ k의 차이는 작업자 수라고 생각하면 됨
데이터 구축 작업 설계 시 유의 사항
- 데이터 구축 기간은 넉넉하게 설정할 것
- 미뤄지는 경우가 비일비재함
- 미뤄지면 어떻게 할 것인가에 대해서 buffer를 두고 일정을 정하는 것이 좋음
- 검수에 충분한 시간을 확보할 것
- 검수 내용을 어느 시점에 어떻게 반영할 것인가 하는 계획을 세울 것
- 품질 미달인 경우의 보완책을 마련할 것
- 원시 데이터를 10~20%정도 여유를 두고 수집하는 것이 좋음
- 작업 난이도에 따라 참여 인력을 산정하고, 참여 인력 모집 및 관리를 어떻게 할 것인지 고민할 것
- 작업자들을 지속적으로 교육하면서 작업을 할 것이라면 QA를 어떻게 할 것인지 생각해야 함
- QA를 어떤 채널로, 누가 답변할지 등등
- 작업자들을 지속적으로 교육하면서 작업을 할 것이라면 QA를 어떻게 할 것인지 생각해야 함
- 각 단계별 작업의 주체를 고려할 것
- 각 단계별 검수 유형을 지정해둘 것
- 외부 인력 및 자원을 활용하는 경우 비용 산정을 위해 기본 단가 산정 기준을 잘 세울 것
- 실제로 업무를 할 경우에는 외부 자원을 활용하는 경우가 많을 것이기 때문에 비용 산정도 중요
- 한 가지 정답만 있는 것이 아니기 때문에 다른 사람들의 경험을 참고하되 자신만의 기준을 세워나가는 것을 추천
참고 문헌
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)