(NLP 기초대회) N2M - Encoder-Decoder Approach
이 색깔은 주석이라 무시하셔도 됩니다.
N2M (Encoder-Decoder Approach) 이론
N2M과 Encoder/Decoder
- N2M 태스크와 Encoder-Decoder 모델의 역할
N2M
N2M 태스크
N개의 데이터를 입력으로 받아 M개의 데이터를 출력하는 태스크
Encdoer + Decoder 모델이 주로 활용됨
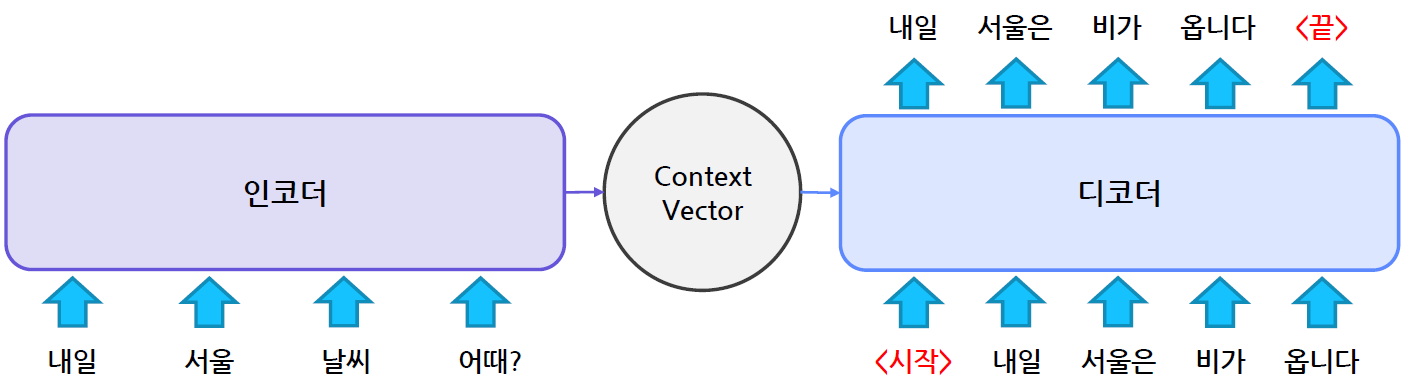
Encoder
입력 정보를 잘 인코딩(숫자화)하기 위해 활용함
긴 Sequence 정보를 잘 추출하는게 중요함

Decoder
인코더에서 인코딩된 정보를 활용하여 출력 Sequence를 순차적으로 생성함
인코딩된 정보와 앞서 생성된 토큰을 함께 활용하여 다음 토큰을 생성함
N2M 태스크 예 | 번역
문장을 입력받아 다른 언어로 번역하는 문제

N2M 태스크 예 | 품사태깅
입력된 문장의 구성요소들의 품사를 맞추는 문제
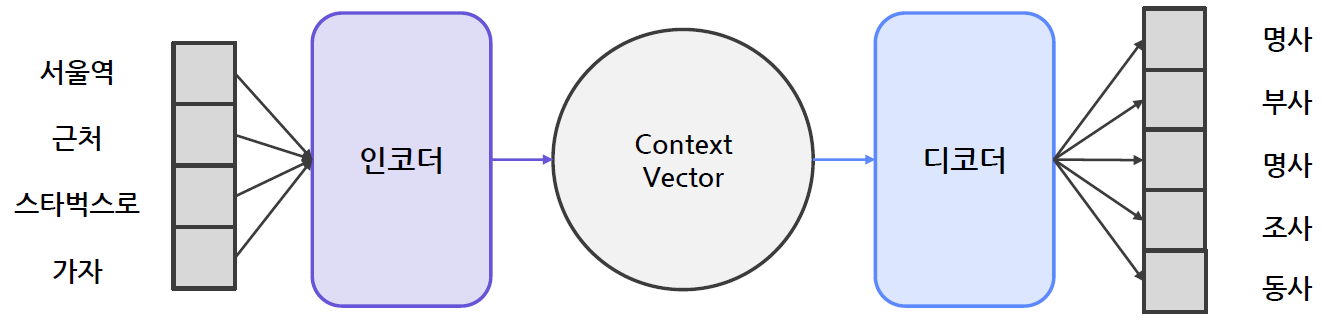
- 품사태깅은 N2N 문제였는데 한국어의 경우에는 N2M 문제가 되기도 함
N2M 태스크 예 | 대화 모델링
질의응답(챗봇 등)
질문에 답변을 하는 문제로, 챗봇이나 문제풀이 등에 활용할 수 있음
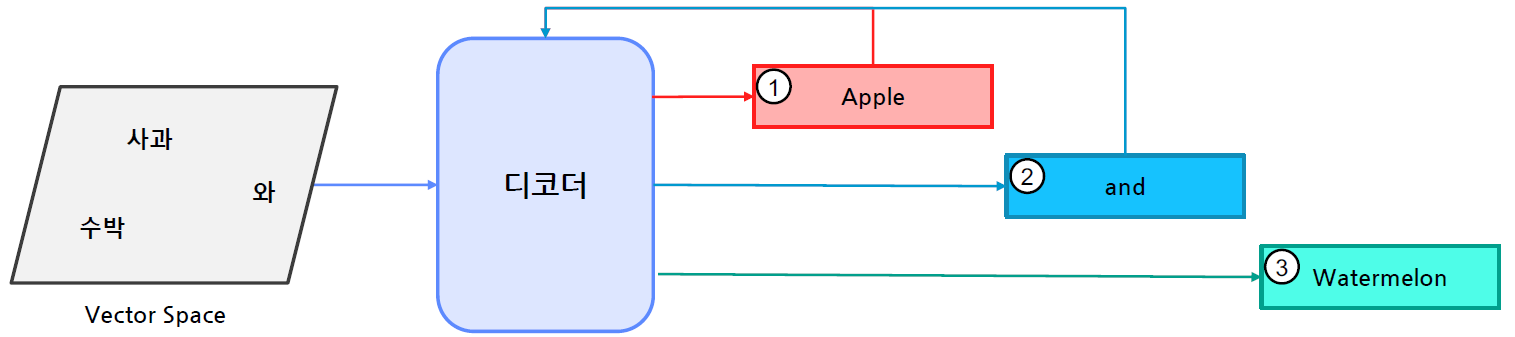
N2M 태스크 예 | Image to Text
이미지 태깅
입력 받은 이미지를 텍스트로 설명하는 문제

Encoder-Decoder 모델
- Encoder-Decoder 모델 종류와 특징
Encoder-Decoder 모델의 발전
Encoder-Decoder 모델 발전 순서

Encoder-Decoder RNN
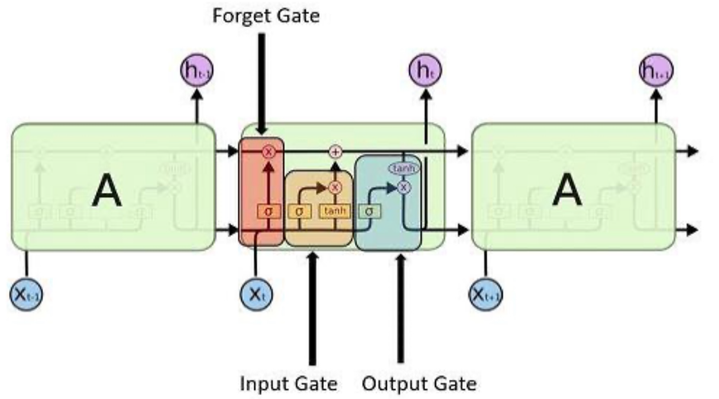
- 대표적인 모델로 LSTM이 주로 사용됨
- LSTM은 이전 입력 정보를 선택적으로 활용할 수 있음
- 데이터가 길어지면 성능이 하락하는 문제가 있음
Attention

Attention
- RNN 구조의 한계를 개선하기 위해 제안된 방법
- 입력 정보에 가중치를 적용하여 정보를 취사선택하는 방법
- 생성해야 할 토큰에 적합한 입력 정보를 골라서 사용함
Additive Attention(Bahdanau Attention)

- 가중치를 더해서 Attention을 적용하는 방법
Multiplicative Attention(Dot-production Attention)

- 가중치를 곱해서 Attention을 적용하는 방법
- 트랜스포머에서 가장 많이 쓰이는 Attention 방법
Transformers

Attention만으로 구현된 Encoder-Decoder 모델
주로 대규모 데이터로 선학습(Pre-training)하여 사용함
N2M 태스크에 특화된 모델
Encoder와 Decoder를 단독으로 사용하기도 함
디코더는 가장 아래 레이어에서 Masked Multi-Head Attention 레이어를 사용
cross attention 적용
- 인코더의 top 레이어 결과물이 디코더의 multi-head attention에 입력으로 들어옴
Transformers 모델 종류

Encoder Only
정보를 양방향으로 취합함
분류 문제에 주로 활용됨

모델 학습방법
손상된 문장을 복원하거나, 문장 간의 관계를 유추하여 학습함
Masked Language Modeling(MLM)

Next Sentence Prediction(NSP)

Decoder Only
정보를 단방향으로 취합함
생성 문제에 주로 활용됨

모델 학습방법
Auto-regression
생성한 단어를 다시 입력으로 사용하여 모든 단어를 순서대로 예측함
Encoder-Decoder 모델
BART
BERT와 GPT를 결합한 모델
손상된 문장을 활용하여 다양한 선학습 방법을 적용하였음

T5
모든 입출력을 Text로 구성하여 학습함
키워드를 활용하여 입력에 태스크 정보를 함께 제공함

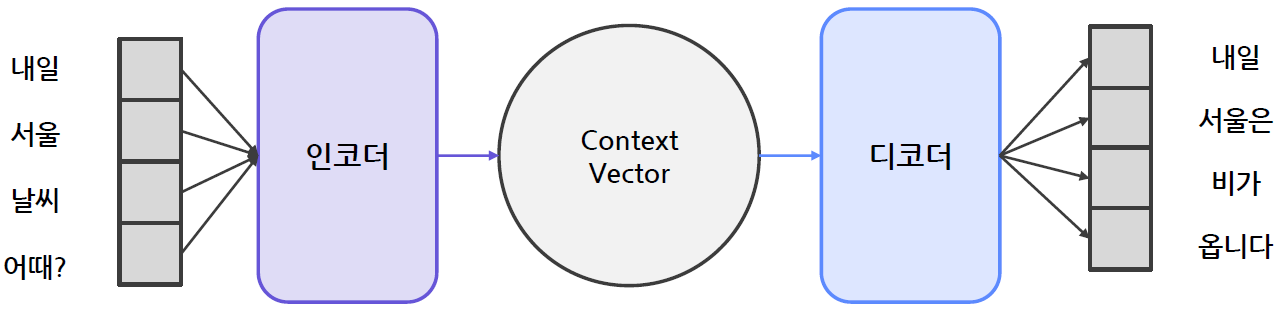
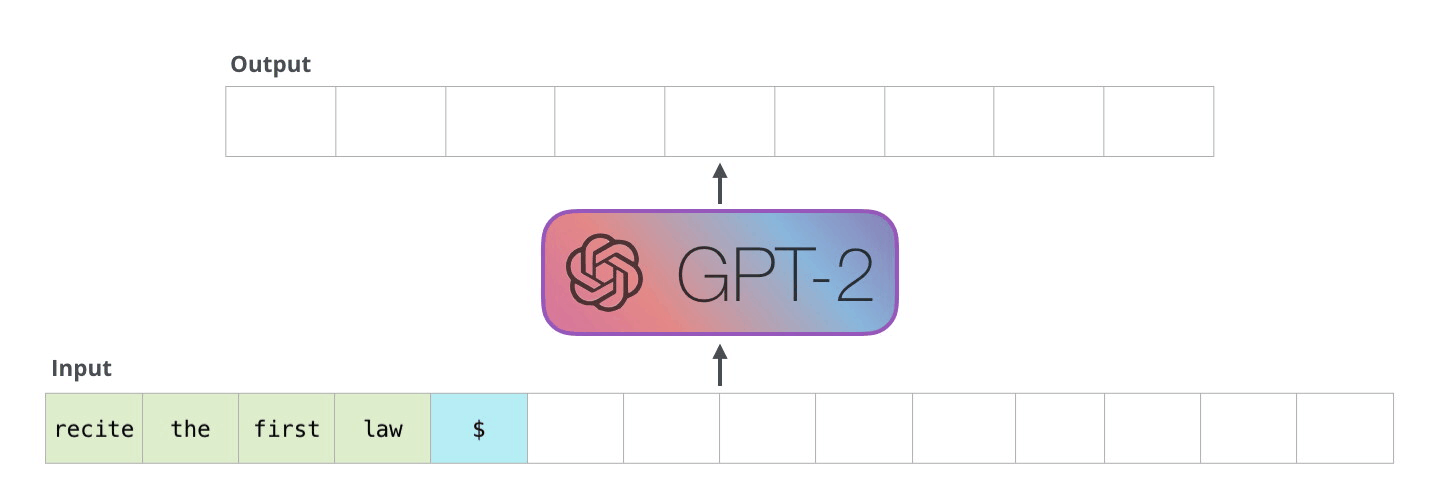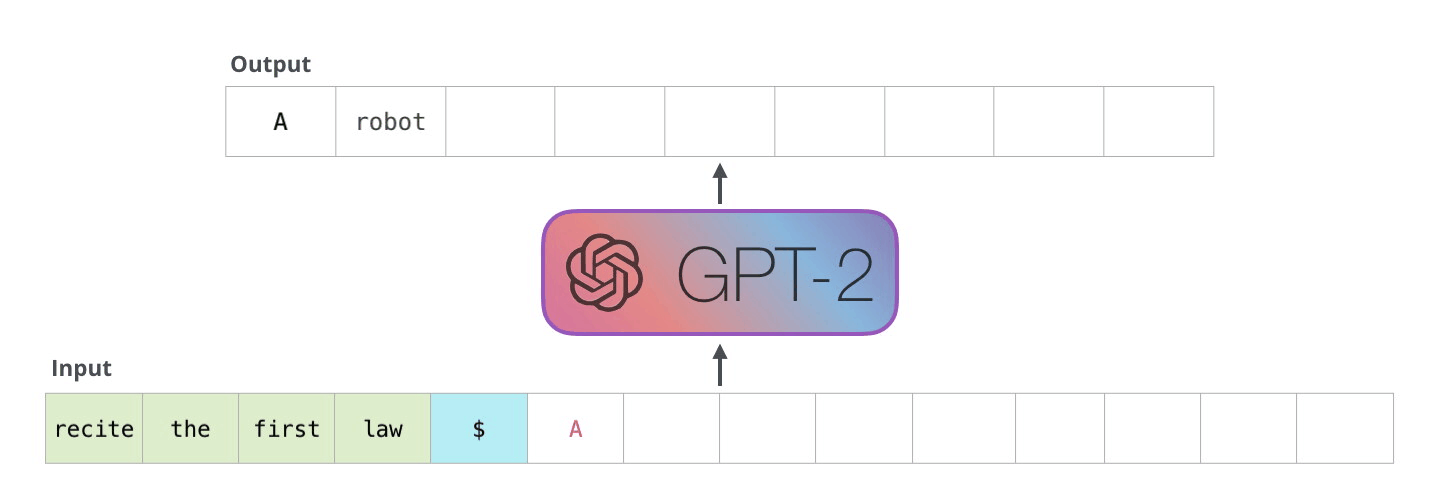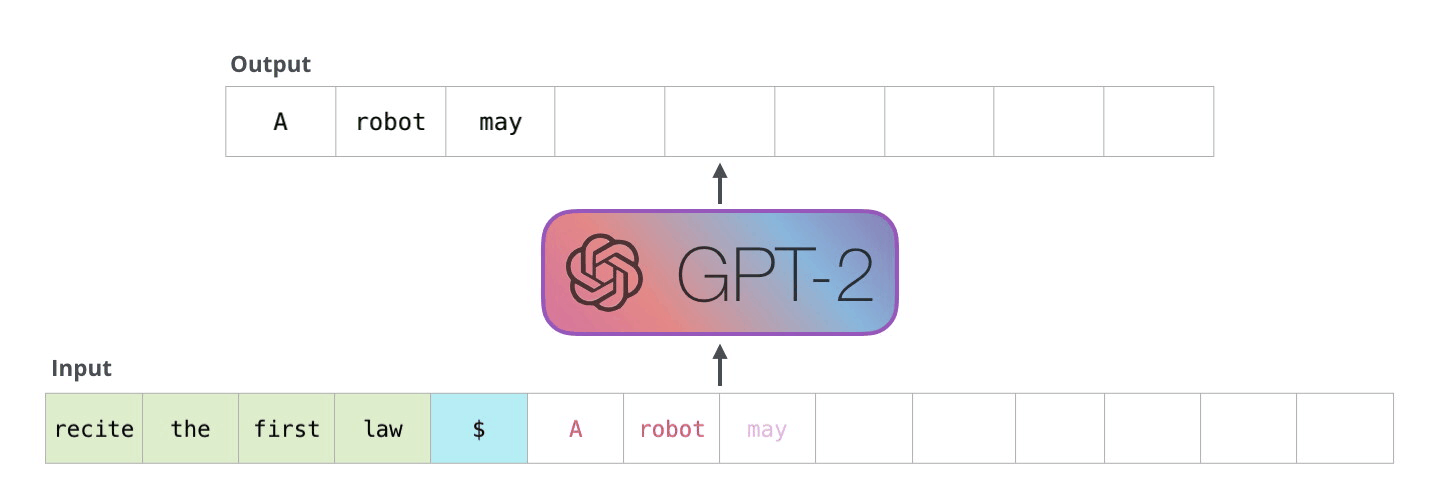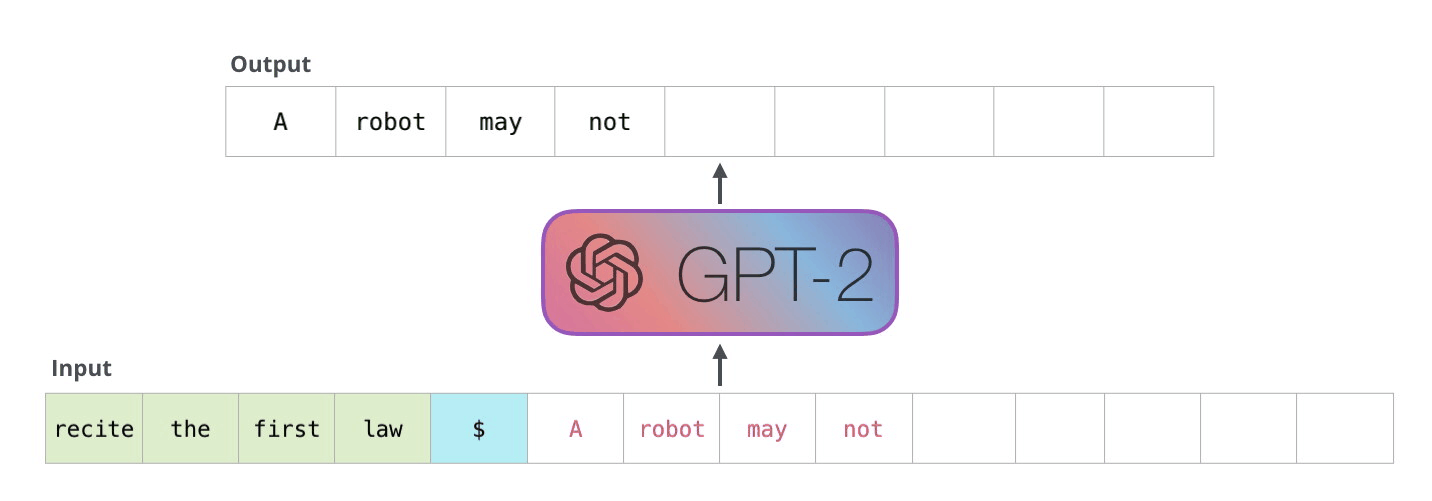
Encoder-Decoder 동작 과정
Encoder-Decoder 동작 과정 예시





Decoding 방법
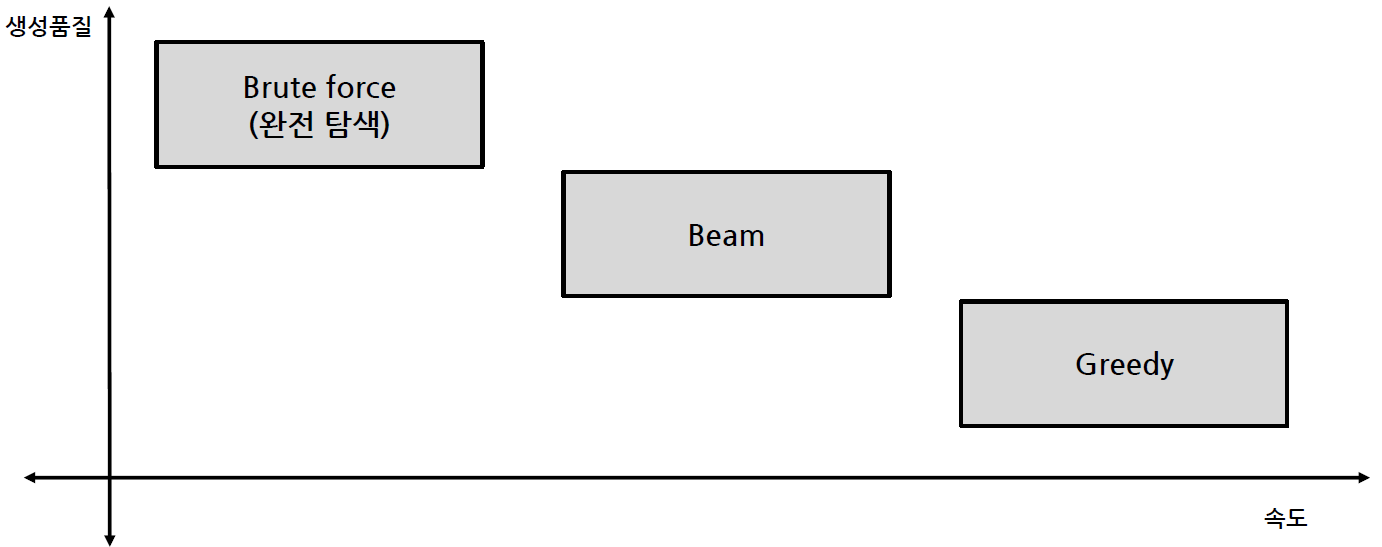
Decoding Strategy
Searching 방법
개선 테크닉

Greedy search
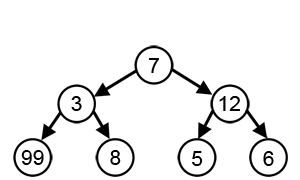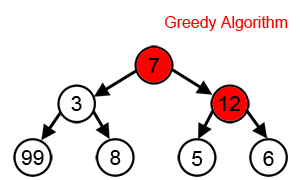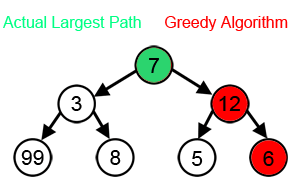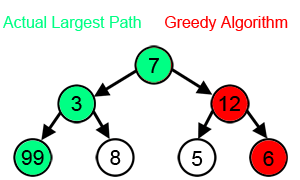
- Greedy 알고리즘을 활용한 디코딩 방법
- 매 순간 현재 상태에서 가장 이익(확률)이 큰 것을 선택함
- 시간 복잡도는 좋지만, 최종 결과가 최선이 아닐 수 있음
- 내일 서울 날씨 어때? -> 내일 서울은 비가 옵니다

Beam search

Greedy보다 더 많은 경우의 수를 고려함
매 순간 N개의 후보를 함께 선택하여 최종 결과를 선택함
N=1 이면 Greedy search와 동일함
항상 최선의 결과가 나오지는 않음
내일 서울 날씨 어때? -> 내일 서울은 비가 옵니다

Beam이 2개인 예시
Decoder Tools | huggingface
Huggingface Generate 함수

출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)