부스트캠프 AI Tech 4기
(NLP 기초대회) N2N - Token Classification 실습
쉬엄쉬엄블로그
2023. 7. 26. 10:47
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
N2N (Token Classification) 실습
데이터셋
KLUE-DP 데이터셋

- 입력 : 어절 단위 한국어 텍스트
- 출력 : DP 태그
- 개수 : 입력과 출력이 동일
- 이를 위해, BIO 태그를 붙이는 전처리가 필요

모델 설명
사용 모델
-
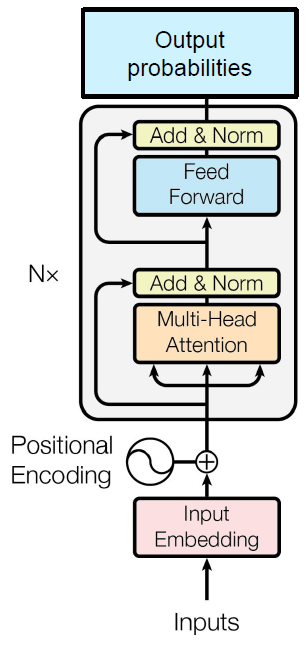
- pre-trained BERT 아키텍처 활용
- bert-base-multilingual-cased Config 활용
- bert-base-multilingual-cased Tokenizer 활용
토크나이징 방법
- Huggingface AutoTokenizer
- Vocab 정보
- 크기 : 50265
- 문장 최대 길이 : 512
- 샘플 데이터
- 입력 : 아이는 예정보다 일찍 태어나
- 출력 : [B-NP_SBJ, I-NP_SBJ, I-NP_SBJ, O, B-NP_AJT, I-NP_AJT, I-NP_AJT, I-NP_AJT, O, B-AP, I-AP, O, B-VP, I-VP, I-VP]
- 토큰화 결과
- 입력 : [101, 9519, 9638, 9043, 100, 9576, 9670, 9356, 9056, 100, 9641, 9728, 100, 9854, 9546, 8982, 102, 0, 0, …]
- 출력 : [0, 33, 5, 5, 32, 52, 55, 55, 55, 32, 42, 44, 32, 65, 66, 66, 0, 0, …]
- 101 = [CLS], 0 = [PAD], 102 = [SEP]
- Vocab 정보
Loss function
CrossEntropyLoss 예시

평가
- Conlleval-2000을 활용한 sequence labeling 평가
Conlleval-2000

- Perl 스크립트
- Python으로 변환된 라이브러리 활용 예정
- F1-score를 제공
- 각 라벨 별 F1-score
- Micro F1-score
- Weighted Macro F1-score
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)