(NLP 기초대회) N2N - Token Classification
이 색깔은 주석이라 무시하셔도 됩니다.
N2N (Token Classification) 이론
N2N 문제 정의
Sequence Labeling

- 문장 전체를 살피고, 특정 part의 의미나 역할을 분석할 때 사용
배경 설명

N21, N2M으로도 풀 수 있는 문제 아닌가?
하나의 토큰마다 여러 번 걸쳐서 예측한다면 N21도 가능은 하지만 낭비가 심할 것
N2M 문제는 출력 개수를 정할 수 없기 때문에(출력 개수가 보장되지 않기 때문에) N개의 딱 맞는 출력을 생성하기에 적합하지 않음
트랜스포머를 활용할 때는 구조 자체가 N개 입력에 대응하는 N개 출력이 나오도록 되어있기 때문에 쉽게 N2N 문제가 모델링 됨
N2N : Encoder 모델을 활용한 sequence labeling task

- Text에 대해 동일한 길이의 label sequence를 출력
- 입력 : 문장, 혹은 문단
- 출력 : 모든 토큰에 대한 class label 분포
- Text에 대해 동일한 길이의 label sequence를 출력
전체 process

HuggingFace N2N API
Huggingface TokenClassification을 활용해 간단하게 훈련이 가능

https://huggingface.co/docs/transformers/tasks/token_classification
데이터의 표현
입력 형태
입력 시 데이터는 task에 알맞게 다양한 형태로 sequential하게 표현

Transformer vocabulary에서 많이 활용하는 형태

출력 형태
출력 시, 입력과 토큰 개수를 동일하게 정해야 함
앞서 표현된 입력의 개수에 맞게, 토큰 개수를 조정

- 대체로 part의 명확성을 위해, Character 단위를 많이 사용
IO : I(label 있음), O(label 없음)
BIO : B(label 첫 글자), I(label 있음), O(label 없음) - 가장 많이 사용되는 방법
BIOES : B(label 첫 글자), I(label 있음), E(label 끝 글자), S(label 1 글자), O(label 없음)


Loss 함수
- N2N 문제에 적절한 Loss 함수는 무엇인가?
적절한 loss 함수의 필요성
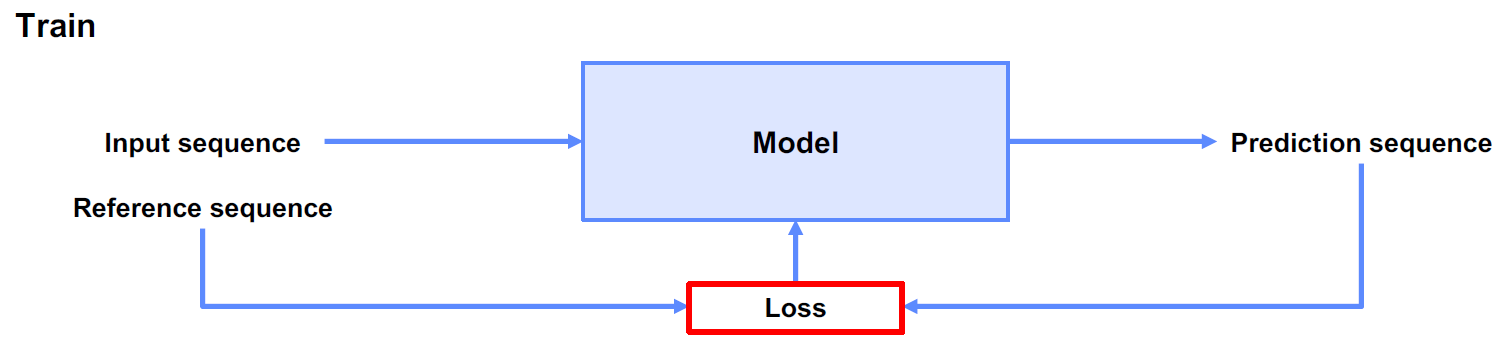
- Sequence Labeling task에 대해 적절한 loss function이 있어야, 훈련에 반영이 가능
- N21 문제와 유사하지만 조금 다른 점이 있음
- N개의 입력, N개의 출력, N개의 정답
- N번의 classification 결과를 종합하는 방식이 들어가야 함
- N21 문제와 유사하지만 조금 다른 점이 있음
Loss for Classification | Cross Entropy

- 여기에서도 CE 사용
Loss for Classification | Cross Entropy | N2N

Sequence labeling에서의 loss 적용

- ignore index
- 출력 y에 해당하는 정답 label이 ignore index가 아닐 때만 수식(loss)을 계산함
- ignore index가 마킹되어 있는 n개의 서브단어는 실제 loss 값에 반영이 되지 않도록 처리해줌
- pytorch에서 정의한 CrossEntropyLoss 메서드에서는 ignore_index를 -100이라고 정의해둠
- -100이라는 값이 나오면 그 토큰은 loss 값에 반영되지 않음

- tip : pad에 대응되는 label로 -100을 넣으면 CE loss를 계산하지 않음
[참고] Transformer 모델의 최대 입력 길이
입력 시 더 긴 text는 배제하기 때문에, 입력 길이를 잘 고려하여 모델을 선택

평가
- N2N 문제에 대한 평가 방법
evaluation metrics
Classification의 주요 평가 Metric

- NLP에서는 보통 F1 score와 Accuracy를 많이 사용
N2N의 경우, 각 라벨에 대한 결과가 생성 (예 : 형태소 분석)
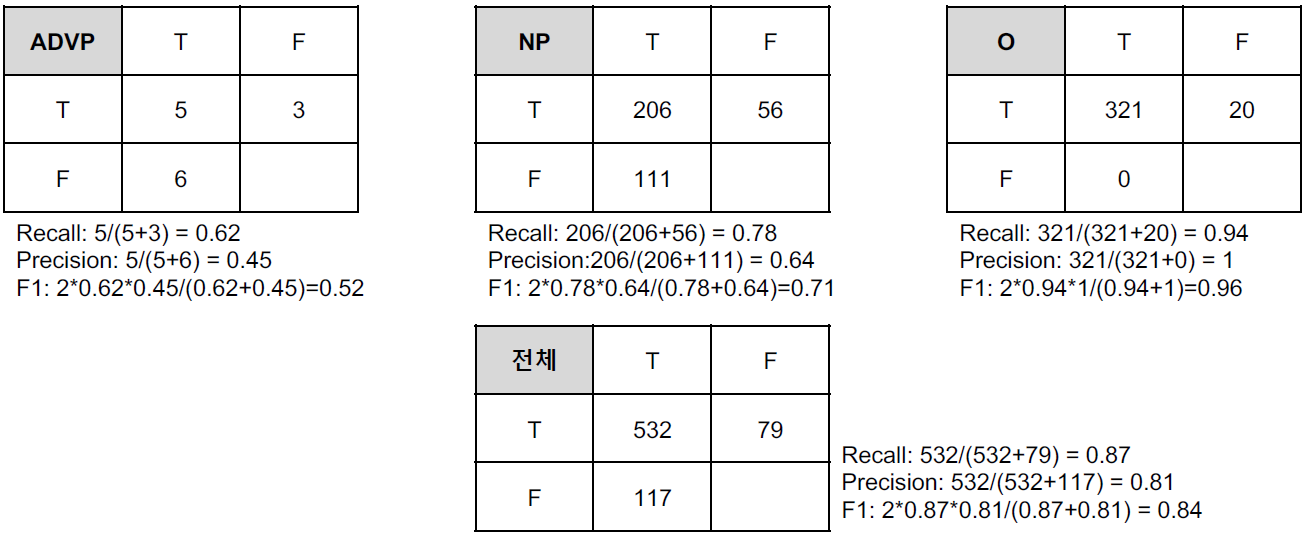

- Macro
- 모든 label을 고려한다.
- 각 라벨별 결과 도출 후, 이에 대한 평균 계산
- Micro
- 전체만 본다.
- 라벨에 대한 제한 없이, 전체 데이터에 대한 결과 계산
Conlleval-2000
- 현재까지도 기준으로 통용되는 sequence labeling measure
- Perl 스크립트로 제공


출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)