(NLP 기초대회) N21 - Sentence Classification
이 색깔은 주석이라 무시하셔도 됩니다.
N21 (Sentence Classification) 이론
Neural Network based Classification
접근방법

- supervised learning (교사 학습)
- 예제 문제를 풀게하고
- 정답과 비교하여
- 잘 맞추는 방향으로 학습
- 구현하기도 쉽고 성능도 안정적으로 올라감
- 하지만 사람들이 직접 데이터를 구축해야 하는 단점이 있음
- classification (분류)
- 가장 높은 숫자를 부여받는 class가 선택되도록 학습
감성 분류기 구현 예
- 감성분석
- 다음에 또 가려구요! - Positive
- 이게 좀 비좁은 느낌을 가져다 줄지도! - Negative
- 역시나 비싼 호텔인가 싶었어요. - Neutral
- 무료 Wi-Fi - Objective
- Class 설계 (4개 Class)
- Positive (긍정)
- Negative (부정)
- Neutral (중립)
- Objective (객관)
신경망 디자인
Design

Prediction

- 3번째 클래스의 결과값이 가장 크기 때문에 3번째 클래스인 중립이 결과가 됨
간단한 수준의 신경망 예

- 뉴럴 네트워크는 일종의 그래프 방식으로 디자인 가능함
- 그래프의 선에 해당하는 하나하나가 파라미터와 일대일 대응 됨
- 보통 FC 레이어에서는 bias까지 포함됨
- 그래서 위 그림에서는 4x6개의 파라미터가 필요
신경망 분류 기법
하위 문제들

- Reference Representation
- 정답 표현
- Scoring Normalization
- 점수 정규화
- Cost Function Design
- 비용 함수 설계
- Parameter Update
- 파라미터 갱신
- Reference Representation
정답표현
정답을 어떻게 표현할 수 있을까?
다음에 또 가려구요! [Positive]

- 긍정의 정도를 다르게 하지 않고 긍정이라면 Positive class에 1을 부여
- classification 방법의 기본적인 가정은 두 가지의 한계를 가짐
- 4가지 감성들이 있을 때 하나의 감성만 출력이 가능
- 감성 안에서도 여러가지 정도가 있을텐데 그런 정도는 표현하지 않음
Score Normalization

- 예측과 정답을 서로 비교하기 위해서는 서로 같은 Scale의 값이어야 한다.
Softmax
Softmax Function

- 0.0 ~ 1.0의 값으로 변환
지수 함수의 특징($e^x$)

- 어떤 값이든 양수 값으로 바꿔줌
- 큰 값일수록 더욱 크게 만들어줌

Cost Function

- 예측 값과 정답 값의 범위를 맞춰줬다면 예측 값과 실제 정답이 얼마나 같거나 다른지 비교해야 함
- loss fucntion, cost function, object function은 모두 같은 의미를 가짐
- cost function은 미분이 가능해야함
- 분류 task에 있어서는 Cross Entropy라는 좋은 cost function이 이미 만들어져있음
- 예측과 정답이 얼마나 같은지 다른지를 계산하는 문제를 형태를 바꿔서 A라는 확률분포와 B라는 확률분포가 얼마나 유사한지 접근할 수 있음
- 그러한 metric이 통계, 확률쪽에서 잘 정의되어 있음
- 바로 KL-Divergence
- KL-Divergence는 방향성이 있음
- A라는 확률분포가 B라는 확률분포로 가는 것, B라는 확률 분포가 A라는 확률분포로 가는 것의 점수가 서로 다름
- 수식적으로 KL-Divergence의 방향성을 없애놓은 버전이 바로 Cross-Entropy가 됨
Parameter Update
어느 방향으로 학습을 진행해야 하는가?

- 오류가 작아지는 방향으로 진행

오류가 작아지는 방향이란 어느 쪽인가?
얼마나 고쳐야 오류를 작아지게 할 수 있을까?
- 방향과 양을 고려해서 파라미터를 업데이트해야 함
- 이러한 부분의 연구는 이미 뉴턴이 해놨음 → gradient descent
방향을 결정하는 방법

- 위 그림의 지점에서의 기울기 방향을 구해서, 기울기가 작아지는 방향으로 간다면, 오류를 작게 만들 수 있을 것
- 미분, 기울기 = Gradient
정리

- 위 프로세스의 흐름이 전형적인 신경망 기반 훈련 / 예측의 구조가 됨
- 위 과정을 보통 PyTorch, TensorFlow 등 여러가지 라이브러리에서 1step이라고 부름
- 1step : Feed Forward부터 Back Propagate까지 이루어지는 것
- 1step마다 파라미터가 업데이트 됨
N21 Problem
What is N21 Problem?

- N개의 입력으로 1개의 출력을 구하는 문제
- Encoder + Fully Connected Layer 형태의 모델을 사용
- 현 시점에서 가장 안정적인 성능을 보이는 Transformer를 기본 Encoder로 설명함
- ex) Topic Classification, Semantic Textual Similarity, …
- N개의 입력이 들어와서 C개의 class에 해당하는 확률분포가 출력되면 그 확률분포를 이용해서 정답을 예측함
Encoder + Linear
Encoder 기반 분류기의 구조

https://ratsgo.github.io/nlpbook/docs/language_model/transformers/ Input / Output Modeling
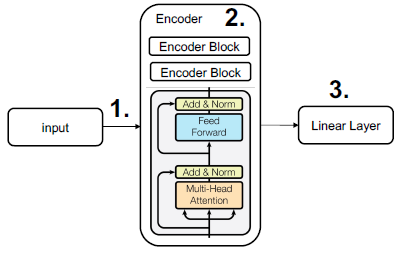
https://ratsgo.github.io/nlpbook/docs/language_model/transformers/ 입력을 적절한 단위로 Tokenization
Tokens에 대해 Encoder가 Sentence Encoding 수행
Encoder의 최종 Output vector를 Classification을 위해 class 개수만큼의 차원으로 Projection

- BertPooler Block을 통해 Projection됨
- activation function으로 Tanh()를 사용하여 -1 ~ 1의 값으로 만들어줌
N21 example
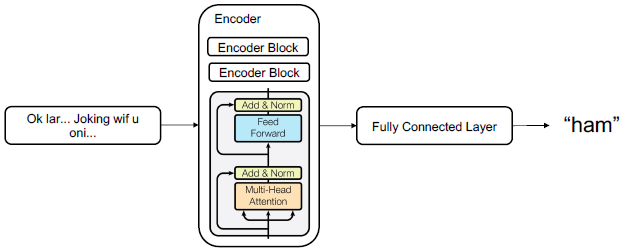
Example : Spam Classifier
Input : SMS(문자메시지)
- ex) OK lar… Joking wif u oni…
Output : 스팸 판별
- ex { ham, ham, spam, ham }
데이터

https://ratsgo.github.io/nlpbook/docs/language_model/transformers/
Example : News Classification (KLUE YNAT)
Input : 뉴스 기사 제목
- ex) 유튜브 내달 2일까지 크리에이터 지원 공간 운영
Output : 기사의 주제
- ex) 3 (생활문화)

Input / Output
Input

Transformer 계열에서의 Input 설명
huggingface의 문법 기준 예제


input_ids
- tokenization vocab에서 각 단어가 몇 번째 id에 해당하는지 나타냄
attention_mask
- 트랜스포머 안에서 문장에 대해서 self-attention이 여러 번 일어날텐데 그 때 attention이 이루어져야 하는 대상을 지정해주는 mask
- 0 또는 1 로 지정됨
- 모두 1로 지정되면 불필요한 정보가 없다는 의미
- self-attention에 고려되어야 하는 정보에는 1을 넣어주고 그렇지 않은 정보에는 0을 넣어줌
- 보통은 batch size에 따라 패딩이 적용되어 가짜 공백을 넣어주기 때문에 pad 토큰에 해당되는 것들은 attention_mask가 0으로 지정됨
token_type_ids
- BERT에서 제안된 아이디어에서 출발
- 2가지 문장이 들어올 때 첫 번째 문장을 0으로 넣어주고 두 번째 문장을 1로 넣어줘서 문장 순서를 구분함
이렇게 가공된 벡터 정보가 뉴럴 네트워크의 입력으로 들어감
Output

- 여기에서 나오는 Logits 값은 아직 확률 값이 아님
- Logits 값에 softmax를 적용해주면 확률 값으로 바뀜
Loss function
N21 - Loss
‘1’에 해당하는 output의 성격에 따라 사용되는 Loss function도 달라진다.

Regression Loss
- MSE (Mean Squared Error)
- Regression 문제에서의 loss function
- $MSE=\frac{1}{N}\sum^N_{i=1}(y_i-\hat y_i)^2$
- ex) y = 1
- $\hat y$ = -0.3028
- MSE = $(1-(-0.3028))^2=1.6972$
- Regression 문제에서의 loss function
- MSE의 자연어처리 적용 예
- MRC(Machine Reading Comrehension) 문제에서의 정답 위치 → 숫자를 맞추는 문제
- 두 문장의 문장유사도 → 숫자를 맞추는 문제
- 추천 등의 문제에서 추천 정도 → 숫자를 맞추는 문제
Classification Loss
- Cross Entropy

출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)