(NLP 기초대회) Transformer
이 색깔은 주석이라 무시하셔도 됩니다.
Transformer - Review for NLP
Transformer
- Transformer 탄생 배경, Transformer에 대한 이해, 자연어처리를 위한 Transformer
기존 NN의 문제점
- 기존의 신경망은 Sequence data에 대해서는 처리하기 어려움

입력이 하나가 들어오면 출력이 하나가 나감
- 자연어는 기본적으로 하나가 들어와서 하나가 나가는 구조가 아님
- 입력이 하나가 들어오고 출력이 하나가 나가는 구조로는 시퀀스 정보를 처리하기에는 쉽지 않음
RNN의 등장

https://ieeexplore.ieee.org/document/7965918 - Sequence data의 처리를 위한 RNN(Recurrent Neural Network) 등장
RNN의 문제점

- 3번의 정보가 2번에 들어올 수 없는 문제가 있음
- 무조건 t-1이 끝나야 t가 생성됨
- 문장이 길어서 토큰이 많아진다면 초반에 있는 토큰의 정보가 마지막 부근에 있는 토큰에 전달되기가 힘들어짐
어떻게 하면 Sequence to Sequence 문제를 잘 해결할 수 있을까?

- RNN의 구조적인 문제를 해결하기 위해서 나온 메커니즘이 attention
- attention의 효과는 번역 task에서 잘 증명됨
- 이 attention을 집적시켜서 만든 것이 트랜스포머 구조
- 어떻게 여러가지 토큰을 쉽게 잘 인코딩할까?
- 어떻게 Long-term Dependency를 잘 인코딩할까?
- 어떻게 순서 정보를 잘 인코딩할까?
- 어떻게 빠르게 인코딩할까?
- 하나의 구조로 여러 문제를 동시에 풀려면 어떻게 인코더와 디코더를 만들어야 할까?
Attention Mechanism
attention을 이해하려면 Blending이라는 개념을 잘 이해하면 도움이 됨
Sequence를 서로 Blending 해보는 건 어떨까?

여러가지 material을 사용하여 Q와 가장 반응이 좋은 material을 만들어보자!
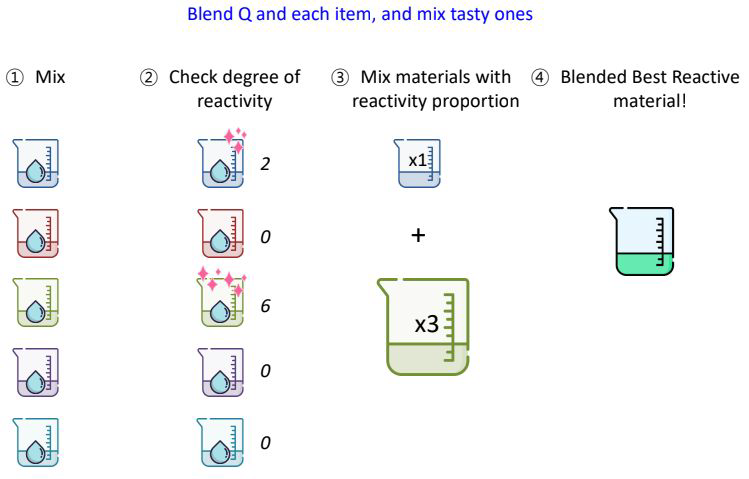
내가 가지고 있는 것들과 Q를 섞어보고
Material과 Q의 반응 정도를 확인해서
반응하는 정도에 따라서 서로 적절히 섞어준다면?
내가 원하는 반응들이 서로 Blending된 material이 나온다!
attention은 관심있는 정보(Q라는 토큰)와 가장 잘 반응하는 토큰을 찾고 그 토큰들만 잘 모아서 새로운 벡터를 만들어내는 기법

앞선 방법의 Q와 material을 Vector로 바꾸어 생각해보면
Query vector와 multiple vectors(material vectors)의 반응 정도를 확인해보고
반응하는 정도에 따라서 서로 적절히 섞어준다면?
내가 원하는 반응들로 Blending된 vector를 얻을 수 있다!
Query와 가장 잘 반응하는 친구들만 선택적으로 모을 수 있는 알고리즘이 attention mechanism임

$x_1,x_2,x_3...$들의 multiple vectors를 Query vector와 반응을 실험해봅니다.
우리는 이 방법을 Attention Mechanism이라고 할 수 있습니다.
다양한 Attention Mechanism

- 다양한 방식이 존재하는데 트랜스포머라는 구조는 위 방식 중 Dot을 확장시킨 Scaled dot이라는 기법을 활용함
Transformer
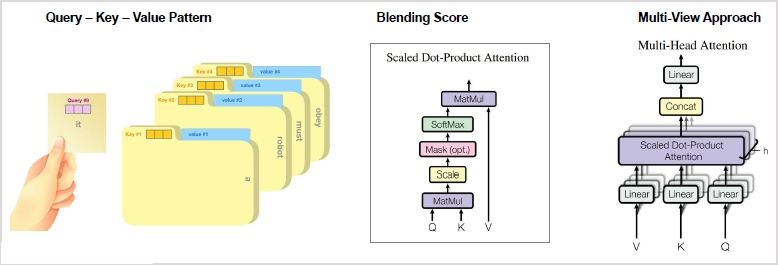
트랜스포머에서는 Query, Key, Value 패턴을 무조건 이해해야 함
- Query와 Key를 먼저 attention score로 조합해보고(scaled dot 연산) 가장 높은 점수를 가진 Key값의 가중치를 이용해서 Value값을 갱신(가중치를 Value 값에 곱)하여 사용
- self-attetnion은 A, B, C 토큰 중에 A, B, C를 섞을 때 외부 정보 Q를 쓰는 것이 아니라 A, B, C를 3번에 걸쳐 섞을텐데 첫 번째 쿼리는 A, 두 번째 쿼리는 B, 세 번째 쿼리는 C로 쿼리를 문장안에 즉, self안에 존재하는 3가지에 대해서 각각 수행하는 것
- attention을 여러 번 사용하여 결과를 종합적으로 보는 것이 multi-head attention
Transformer Architecture

https://ratsgo.github.io/nlpbook/docs/language_model/transformers/ - Transformer는 Encoder와 Decoder Block들이 쌓여있는 구조
- Transformer는 RNN을 사용하지 않고 Attention으로 구성
Encoder Block(Layer)

https://ratsgo.github.io/nlpbook/docs/language_model/transformers/ - Encoder는 아래 세 가지로 이루어져 있습니다.
- Multi-Head Attention
- Feed Forward Network
- Add & Norm
- Encoder는 아래 세 가지로 이루어져 있습니다.
Decoder Block(Layer)

https://ratsgo.github.io/nlpbook/docs/language_model/transformers/ - Decoder는 아래 네 가지로 이루어져 있습니다.
- Masked Multi-Head Attention
- Multi-Head Attention
- Feed Forward Network
- Add & Norm
- Encoder의 현재 hidden state에서 Key와 Value 값을 가져와서 Multi-Head Attention의 입력으로 사용
- Query는 Masked Multi-Head Attention을 거쳐서 나온 값을 그대로 사용
- Decoder는 아래 네 가지로 이루어져 있습니다.
NLP에 적용

- N21, N2N에는 인코더만 사용해도 됨
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)