부스트캠프 AI Tech 4기
(NLP 기초대회) NL Data 관리 및 처리 툴 소개
쉬엄쉬엄블로그
2023. 7. 17. 11:01
728x90
이 색깔은 주석이라 무시하셔도 됩니다.
NL Data 관리 및 처리 도구 소개 - Pandas
Pandas
Pandas
About Pandas
- 대용량 데이터 처리 가능
- Pandas를 이용하면 GB 단위 이상의 대용량 처리
- 테이블과 시계열을 조작하기 위한 데이터 구조와 연산을 제공
- 데이터를 합치고 관계 연산을 수행하는 기능들, 누락 데이터 등을 처리할 수 있는 기능들 외 다양한 기능들을 제공
- 대용량 데이터 처리 가능
Excel-like data form

- Pandas는 기본적으로 “엑셀”과 비슷한 형태의 자료구조들을 지원
- Pandas에서는 “Series”와 “DataFrame”이라는 자료구조를 제공함으로써 데이터 분석을 도와준다.
Series & DataFrame
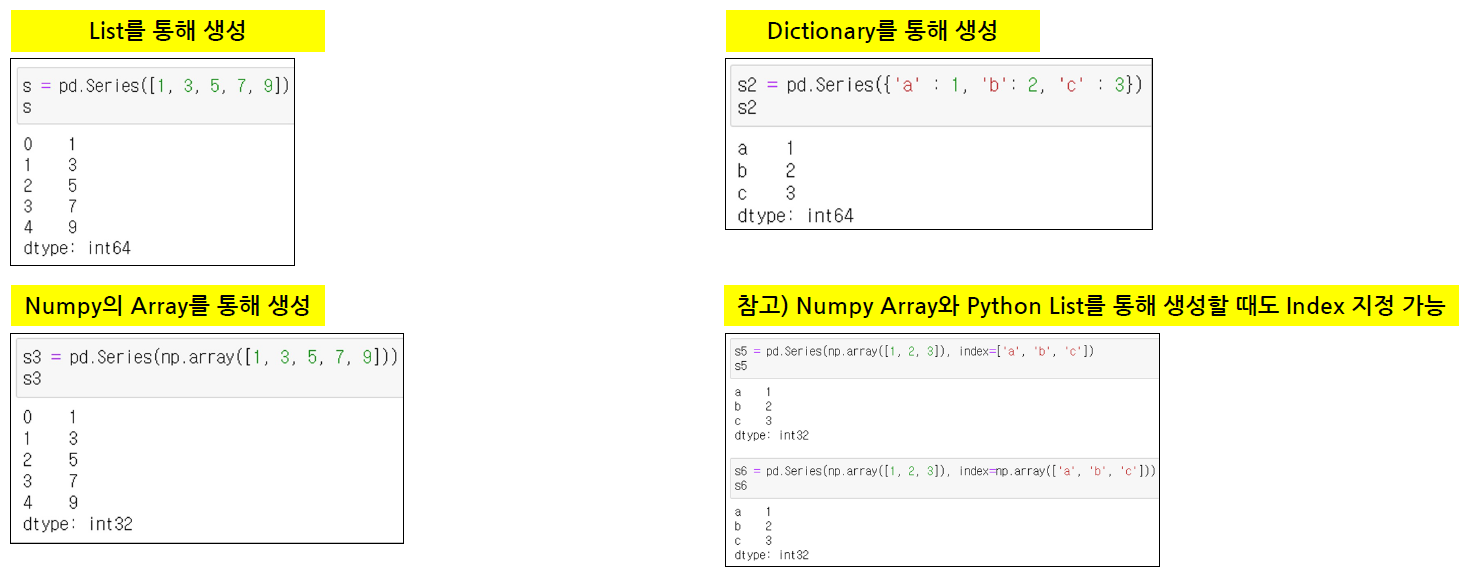
Series : 1차원 배열의 형태

- 인덱스에 의해 데이터가 저장되고 검색
DataFrame : 2차원 배열의 형태

- 인덱스와 컬럼에 의해 데이터가 저장되고 검색
Series 생성
DataFrame 생성

데이터 선택
Column 명과 Row의 범위를 이용하여 데이터 선택


- 주의) ‘가’와 같이 인덱스 이름을 통해 데이터를 가져오기 위해서 df[’가’]라고 하면 KeyError가 발생
- DataFrame은 Column을 Key 값으로 갖기 때문
- 따라서, df[컬럼명]의 형태로만 사용 가능
- df[시작 위치 : 마지막위치 + 1]
- df[”시작 index 이름” : “마지막 index 이름”]
Index의 이름(Row의 이름)으로 데이터 선택

다양한 범위의 위치를 기준으로 데이터 선택

조건을 이용하여 데이터 선택

데이터 분석
행방향으로의 또는 열방향으로의 합 구하기

- reduce function
그 외 함수들

Pandas with NLP
Pandas with NLP
데이터 읽고, 쓰기

- Pandas는 간단한 함수로 데이터를 쉽게 읽고, 쓰게 지원
- 매우 많은 형태의 데이터를 기본적으로 지원
활용할 데이터

- Korean Language Understanding Evaluation(KLUE)의 Natural Language Inference (NLI) 데이터
- 가설 문장과 전체 문장 간의 관계를 추론
- 입력 : premise(전제), hypothesis(가정)
- 출력 : gold_label [진실(entailment), 거짓(contradiction), 미결정(neutral)]
- 3,000개의 문장 쌍
데이터 탐색
Row의 범위와 Column 명으로 데이터 탐색

- 3,000개의 문장 쌍 데이터 중 Row의 범위로 1000개를 선택
- 선택된 데이터의 Column = gold_label 선택
다양한 Column 명으로 데이터 탐색

조건을 이용한 특정 단어가 있는 데이터 탐색
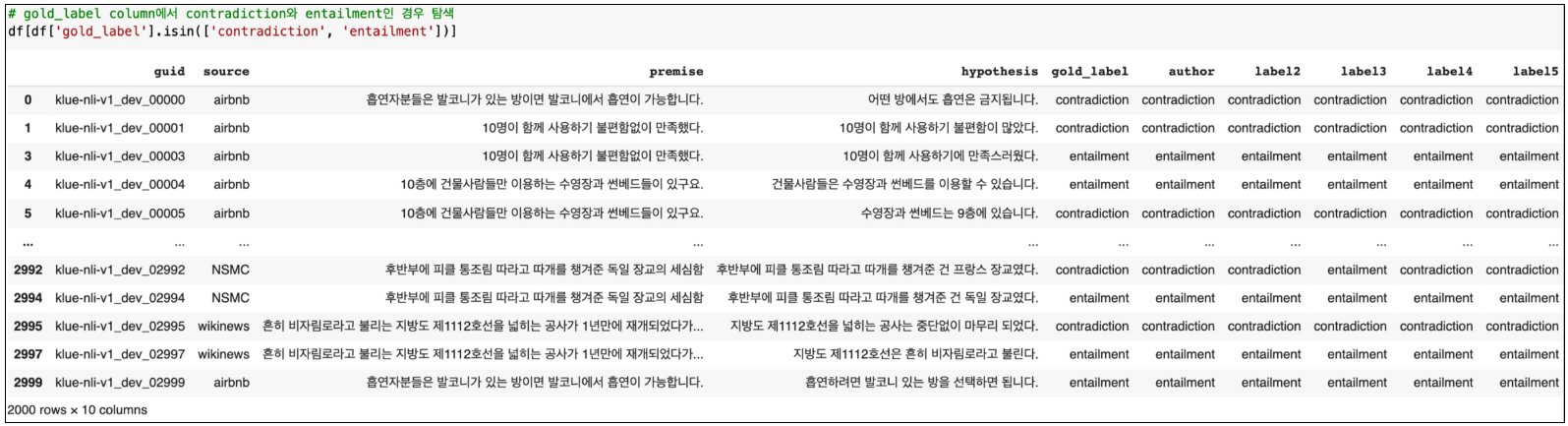
데이터 분석
조건을 이용한 데이터 분석

PyTorch Dataset
PyTorch Dataset에 적용하기
class DF2DataSet(Dataset): def __init__(self, df, max_len=512, truncate=True): # label만 있는 데이터 생성 self.label = df['gold_label'] # label을 숫자로 변환하기 위한 label 모음 self.get_labels = set(self.label) # 문자열을 tensor vector로 변환해주는는 tokenizer 준비 self.tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) # tokenizer로 두 문장 (premise, hypothesis)을 변환하여 입력 데이터 생성 ## 두 문장을 string 타입의 list로 변환 p_text = pd.Series(df['premise'], dtype="string").tolist() h_text = pd.Series(df['hypothesis'], dtype="string").tolist() self.input_data = self.tokenizer(text = p_text, text_pair = h_text, padding='max_length', truncation=truncate, return_tensors='pt', max_length=max_len) def __len__(self): return len(self.label) def __getitem__(self, idx): item = {"inputs": self.input_data[idx], # label을 id로 변환 "labels": torch.tensor(self.get_labels.index(self.label.iloc[idx])), } return item자연어 데이터셋 불러오고 분할하기
# 데이터셋 생성 df_dataset = DF2DataSet(df) # 데이터셋 분할 train_data, test_data = random_split(df_dataset, [2700, 300]) train_data, valid_data = random_split(train_data, [2400, 300]) print('Number of Train data: ',len(train_data)) print('Number of Valid data: ',len(valid_data)) print('Number of Test data: ',len(test_data))
출처: 부스트캠프 AI Tech 4기(NAVER Connect Foundation)